AI SEO:2026年におけるLLMおよびAI検索最適化の完全ガイド
AI SEOとは、単にGoogleで上位表示することではなく、AIの回答に引用されることを指します。本ガイドでは、LLMがコンテンツを処理する仕組み、重要な7つのランキング要因、最適化チェックリスト、そしてAI検索の可視性を測定する方法を網羅しています。
AI 検索の可視性を追跡するインストールなし

更新者
11 最小読み取り
May 22, 2026に更新されました
TL;DR: Googleで1位を獲得しても、ChatGPT、Gemini、Perplexityの回答に表示される保証はもはやありません。AI SEOとは、AI生成された回答の中で引用されるための規律であり、2026年現在、従来の検索と同等、あるいはそれ以上に重要な検索チャネルとなっています。本ガイドでは、LLMがコンテンツを処理する仕組みを7ステップのフレームワークで解説し、AIシテーション(引用)を決定づける15のランキング要因(220万件のプロンプトから特定された3つの新要素を含む)、そしてコンテンツの品質、事実の正確性、技術的なシグナル、ソーシャルプレゼンスを網羅した完全な最適化チェックリストを提供します。
「AI検索はトレンドである」という言説は、もはや過去のものです。2026年、AI回答エンジンは、購買意欲の高いクエリにおいてデフォルトの発見レイヤーとなっています。ChatGPTのユーザーは単にブラウジングするだけでなく、問いかけ、合成された回答を受け取り、行動を起こします。Adobeの小売AIトラフィック分析によると、小売分野におけるAIトラフィックは前年比で4,700%増加しました。AmazonのAIアシスタント「Rufus」だけでも、100億ドル以上の商取引インタラクションを処理しています。
AIの回答で引用されるブランドは、偶然そこにいるわけではありません。AI SEOを通じてその地位を確立したのです。
AI SEOとは何か:定義と範囲
AI SEOとは、ChatGPT、Google AI Overviews(AIによる概要)、Perplexity、Claude、Gemini、Grok、Meta AI、Microsoft Copilot、DeepSeek、Amazon RufusなどのAI検索プラットフォームや大規模言語モデル(LLM)内での視認性と発見可能性を高めるために、コンテンツ、Webサイト、およびデジタル資産を最適化する実践手法です。
検索エンジン結果ページ(SERP)の上位表示を目指す従来のSEOとは異なり、AI SEOはAIが生成する回答の中で参照されることを目的とします。これには、LLMにコンテンツを権威あるものとして認識させるためのトレーニング、機械検索のための情報構造化、そしてAIシステムが信頼性を評価するために用いるクロスプラットフォームなトラストシグナル(信頼のシグナル)を構築することが求められます。
よくある誤解として、AIツールを使ってSEOタスクを行うことをAI SEOと呼ぶケースがありますが、本ガイドの文脈におけるAI SEOは、コンテンツを回答生成AIのニーズに合わせて最適化し、AIが解釈・信頼・提示しやすい状態にするプロセスを指します。
従来のSEO vs. AI SEO:比較表
| 項目 | 従来のSEO | AI SEO |
|---|---|---|
| 第一のゴール | SERPの1ページ目にランクインする | AI生成された回答で引用される |
| 最適化の焦点 | キーワード、バックリンク、メタタグ | 意味的関連性(セマンティック関連性)、明瞭さ、事実の正確性 |
| ユーザー体験 | SERPからWebサイトへのクリック誘導 | クリックの有無に関わらず、即座に回答を提供 |
| コンテンツ形式 | スキャナビリティ(読みやすさ)に最適化 | 機械による理解と再構成に最適化 |
| 測定指標 | ランキング、CTR、セッション数 | シテーション数、ブランドメンション数、AIシェア・オブ・ボイス |
| 主要ツール | Google Search Console, Semrush, Ahrefs | GEOプラットフォーム, AI引用監視ツール |
| 勝ち筋の戦略 | 結果リストの最上位を占める | AIが信頼し、表示させる情報源となる |
AI SEOは従来のSEOに取って代わるものではなく、その上に構築されるものです。SEOの基本原則は依然として基盤となります。変化したのは、順位が高ければ十分という時代が終わったということです。コンテンツ構造、トラストシグナル、意味的明瞭さ、そしてオフサイト(外部)のソースの多様性といった追加レイヤーこそが、AIの回答に表示されるブランドとそうでないブランドを分かつ境界線となります。
AIが検索のルールを根本的に変えている仕組み
従来の検索から生成AIへのシフトは、ハイパーリンクの発明以来、人々が情報と出会う方法において最も重要な変化をもたらしました。発見のメカニズムは、相互に関連する3つの方法で変化しています。
「ゼロクリック」から「ゼロビジット」へ
かつて「ゼロクリック検索」とは、ユーザーが強調スニペットを読んでソースページを訪れないことを意味していました。AI時代においては、ChatGPT内ですべての調査セッションが完結し、外部へのリンククリックが一度も発生しないことも珍しくありません。Ahrefsによる5,580万件のAI Overviewsの分析によると、AI Overviewsが表示されると、ソースページへのクリック率は約34.5%低下します。発見の目安としてオーガニックトラフィックに依存しているブランドにとって、この減少は警告ではなく、すでに現実に起きている事象です。
結論は明らかです。AIが引用する情報源にならなければ、クリックして自分を見つけ出そうとしないユーザー層に対して、自社は「存在しない」のと同じなのです。
検索面(サーチサーフェス)の劇的な断片化
ブランドが可視化されるべきAIサーフェスの数は、1つ(Google)から多数へと増加しています。当初のLLMプラットフォームの波を超え、新たなAI発見環境として、X上のGrok、Instagram・Facebook・WhatsAppに組み込まれたMeta AI、OfficeアプリのMicrosoft Copilot、DeepSeek、GoogleのAIモード、Amazon Rufusなどが加わりました。各モデルはコンテンツの取得および提示方法がそれぞれ異なるため、AI SEOはもはや単一の最適化ターゲットではなく、本質的にマルチプラットフォームな規律となっています。
発見は「コンテキスト重視」かつ「会話型」へ
現代のAI検索は、ニュアンス、インテント(意図)、および関連クエリ間の関係性を理解します。ユーザーはAIシステムに対して事後質問を行い、複数のやり取りを通じて理解を深め、従来の検索ツールではサポートできなかったリサーチセッションを実施しています。ユーザーがChatGPTに対してあなたの製品カテゴリーについて行う検索は、これまで追跡してきたキーワードとは全く異なる可能性があります。そのため、キーワードリサーチと同様に「プロンプトリサーチ」が重要になっています。
LLMがコンテンツを処理し提示する仕組み:7ステップのフレームワーク
AI検索での可視性を効率的に最適化するには、LLMがコンテンツを評価、取得、提示する具体的なステップを理解する必要があります。このフレームワークは、ChatGPT、Perplexity、Geminiなど主要なAIプラットフォーム全体に適用されますが、各ステップの重み付けにはプラットフォーム固有の差異があります。
ステップ1:クエリの理解 — インテントとエンティティの検出
LLMはまずユーザーのクエリを解析し、3つの要素を特定します。それは、ユーザーインテント(購入、比較、学習、情報収集のいずれか)、エンティティ(製品、ブランド、カテゴリー、トピックなどの主要要素)、そして利用可能な場合はパーソナライゼーションのシグナルです。このエンティティ検出フェーズにより、どのブランド、製品、トピックが回答に関連があると見なされるかが決定されます。Webコンテンツ全体で明確かつ一貫したエンティティ定義を持つブランドは、この段階での検出確率が高くなります。
最適化の示唆: ブランド名、製品名、カテゴリーの関連付けが、すべてのWebプロパティで一貫して明確に使用されていることを確認してください。名称の不一致はエンティティの曖昧さ回避を困難にし、引用される確率を低下させます。
ステップ2:関連情報の取得 — 検索インデックスとAPIの活用
クエリを理解した後、LLMは利用可能なソースプールから関連情報を取得します。モデルが静的なトレーニングデータ(デフォルトのChatGPTなど)を使用するか、リアルタイム取得(Perplexityやブラウジング機能付きChatGPTなど)を使用するかによって、参照先は異なります。これには、広範なアクセスのためにインデックスされたWebコンテンツ、Retrieval-Augmented Generation(RAG)を通じたリアルタイムAPI呼び出し、ブランドサイトや製品ページ、サードパーティのレビューや記事、そしてますます重要性を増しているソーシャルメディアのコンテンツが含まれます。Higoodieによる10個のAIサーフェスにおける610万件の引用分析データによると、ソーシャルメディアのコンテンツはAI取得において最も急速に成長しているエビデンス層の一つであり、引用量全体よりも4倍の速さで増加しています。
最適化の示唆: クロール可能性(Crawlability)が前提条件です。robots.txtでAIクローラー(GPTBot, Anthropic-ai, PerplexityBot, Google-Extended)が許可されていること、そして重要なコンテンツがクライアントサイドのJavaScriptではなく、初期HTMLレスポンスで提供されていることを確認してください。
ステップ3:ソースのスコアリングとランキング — 関連性と権威性の決定
LLMは複数の要因に基づいて、取得したソースをスコアリングしランク付けします。クエリとの「関連性」によって、そのソースが真のインテントに対処しているかどうかが決まります。ドメインの評価、他の権威あるソースによるクロスリファレンス、事実主張の一貫性といったシグナルにより、ソースの「権威性と信頼性」が判断されます。時間的な鮮度が求められるトピックでは、「フレッシュネス(鮮度)」が優先されることもあります。コンテンツ内の「感情(センチメント)」もランキングに影響を与える可能性があり、曖昧な内容よりも、情報をポジティブかつ正確に提示するコンテンツの方が優れたパフォーマンスを発揮します。
最適化の示唆: 深さと具体性を通じてトピカルオーソリティ(トピックに関する権威性)を構築してください。特定のトピック領域において複数の権威あるソースから認知されているブランドは、幅広く浅いコンテンツしか持たないブランドよりも、スコアリング確率が大幅に高くなります。
ステップ4:エンティティリンキング — 正確なブランド表現
LLMがコンテンツを提示する際、ブランドへの言及が重複や矛盾なく正確に表現されるよう、エンティティリンキングを行います。このステップは、ブランド名への言及を、モデルがトレーニングデータや取得したコンテンツ全体を通じて構築したエンティティプロファイルに結びつけるものです。NAPデータ(名称、住所、電話番号)、製品名、およびWebソース全体でのポジショニングが一貫しているブランドほど、強力なエンティティリンクプロファイルを保持します。
最適化の要諦: ブランドのデジタルフットプリントを監査し、名称、ポジショニング、事実関係の記述に不整合がないか確認してください。エンティティの混同(モデルが貴社をどの「X」であるか特定できない状態)は、引用される可能性を直接的に低下させます。
ステップ5:回答の生成 — 情報の統合
LLMは、取得した複数のソースの内容を統合し、有用で信頼性が高く、関連性の高い情報を優先して一貫した回答を作成します。出力には、要約、比較表、リスト、あるいは複数のソースから得た知見の組み合わせが含まれます。回答を最初に明確に示し、その後に詳細な背景情報を添えるコンテンツは、前置きが長く回答が埋もれてしまうコンテンツよりも、AIによる抽出(Extractability)が容易です。
最適化の要諦: 戦略的なコンテンツはすべてBLUF(Bottom Line Up Front:結論を先に述べる)形式で構成してください。主要な問いに対する直接的な回答を最初の40~60語で提示し、その後に裏付けとなる文脈や根拠を続けます。
ステップ6:回答内でのブランドランキング — 関連性と品質
LLMは、最終的な回答に含めるべき最も関連性が高く、品質の高いブランド、製品、またはソースを判定します。ランキングは、クエリの意図に対する関連性、およびセンチメント(感情指標)、データの品質、コンテンツがどの程度専門知識を示しているかという品質シグナルに基づいて決定されます。ブランドの機能に関する肯定的、具体的、かつ事実に基づいたコンテンツは、引用される確率を高めます。
最適化の要諦: 具体的な裏付けデータとともに事実関係を客観的に示すコンテンツは、曖昧な言葉や宣伝文句ばかりのコンテンツよりも一貫して高いパフォーマンスを発揮します。可能な限り統計データ、比較情報、専門家による引用を含めてください。
ステップ7:出力フィルターの適用 — 安全性と正確性
最後に、LLMは出力フィルターを適用し、回答が安全性、正確性、コンプライアンス基準を満たしているかを確認します。これらのフィルターは、ハルシネーション(幻覚)の可能性、ブランドセーフティ、そして昨今重要性を増している法的・規制遵守を確認します。信頼できるソース全体で一貫して正確な情報が提供されているブランドは、ハルシネーションフィルターに引っかかる可能性が低く、AIが自信を持って引用する可能性が高まります。
最適化の要諦: AIが生成する貴社ブランドの説明文に不正確な点がないか、定期的に監査を行ってください。自社サイト内だけでなく、他社サイト上で自社ブランドが記述されている場合も、事実誤認があれば修正を依頼してください。Web上の不正確なコンテンツは、そのままAIの不正確な回答へと変換されてしまいます。
AI検索環境における主要なランキング要因
2025年1月から6月にかけて、ChatGPT、Claude、Perplexity、Grok、Gemini、Google AI Modeといった主要なプラットフォームにわたる220万件の実際のユーザープロンプトを分析したHigoodieの調査により、AIの回答に引用されるかどうかを決定する15の核心的な要因が特定され、5つのカテゴリーに分類されました。
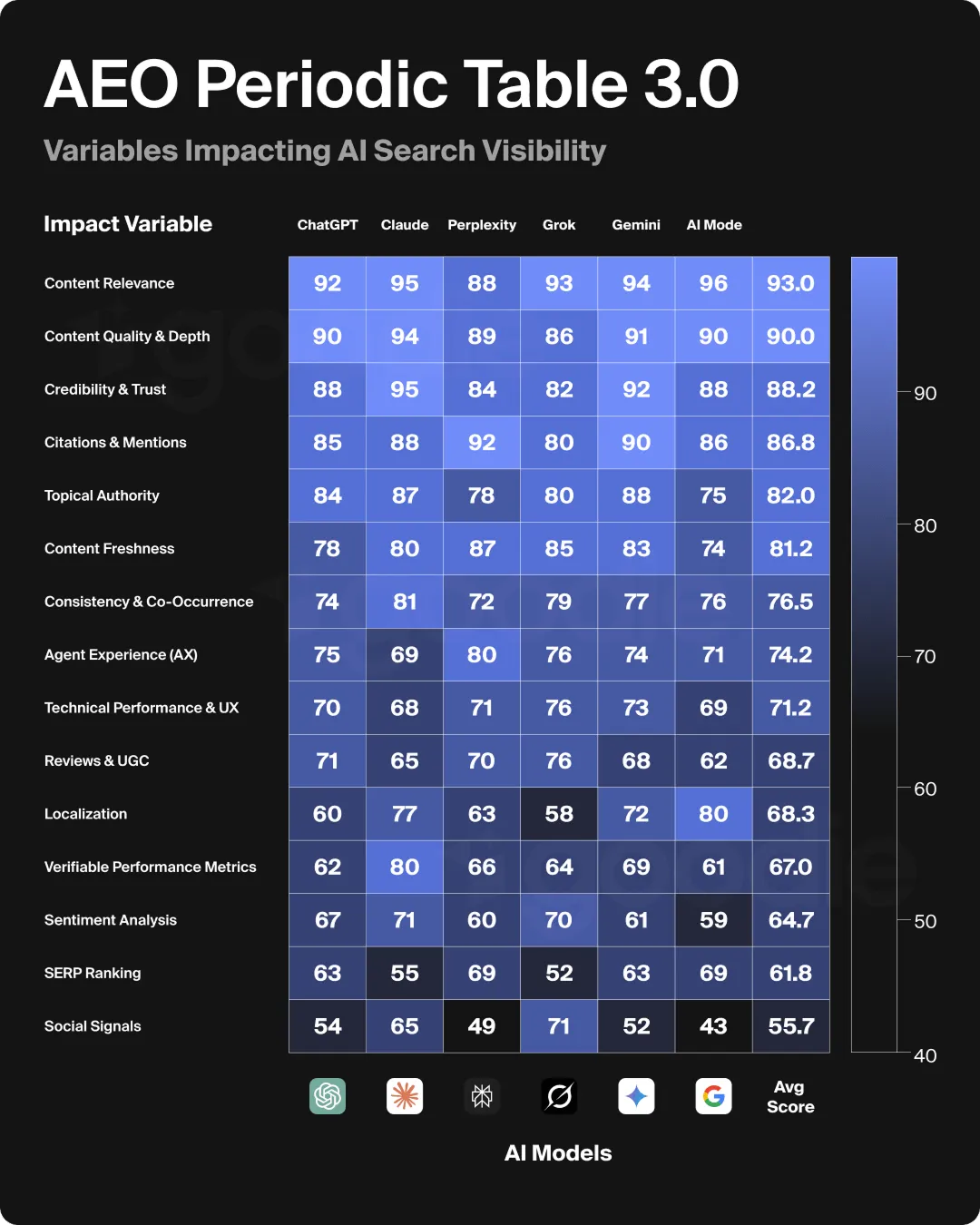
カテゴリー1:コンテンツシグナル
コンテンツシグナルは、AIシステムが貴社のコンテンツを理解し、検索結果として提示するための基盤となる要素です。最も重要なのは、トピックへの関連性(ユーザーの意図とコンテンツがどれだけ適合しているか)、構造の明確さ(AIが解析・抽出可能な構成になっているか)、そして鮮度(最新情報を反映しているか)です。FAQセクション、ハウツーガイド、構造化された比較コンテンツは、特定の質問に直接答えるよう設計されているため、AIの引用ソースとして非常に高いパフォーマンスを示します。
カテゴリー2:オーソリティと信頼性
AIシステムが貴社ブランドをどの程度信頼できると見なすかは、シグナルの組み合わせによって決定されます。これには、ブランドを言及またはリンクしているドメインの権威性、ソース間での事実関係の一貫性、専門家の執筆者や資格の存在、そしてレビュー、ケーススタディ、論評を通じた第三者による検証などが含まれます。「V3 AEO Periodic Table」の研究によると、査読付きの引用やデータに基づいたケーススタディを持つブランドは、トピックオーソリティのスコアが平均17%向上しました。
カテゴリー3:エンゲージメントと社会的証明
レビュー、コミュニティでの議論、SNSシェア、UGC(ユーザー生成コンテンツ)などのシグナルは、実際のユーザーにとってのコンテンツ価値を示すものであり、AIシステムはこれらのエンゲージメントシグナルをコンテンツの信頼性を測る代替指標として解釈します。関連コミュニティにおける貴社ブランドに関する本音のReddit議論は、特にPerplexityやChatGPTにおいて、一貫してAIによる引用のトリガーとなります。
カテゴリー4:技術的パフォーマンス
ページの読み込み速度、クローラーの巡回しやすさ(Crawlability)、スキーママークアップの実装、構造化データの品質といったインフラ面の要素が、AIによる発見可能性(Discoverability)に影響を与えます。主要なAIプラットフォームの中で、Grokは技術的パフォーマンスの重み付けが最も高く、X(旧Twitter)のクローラーを優先する仕組み上、高速なコンテンツ配信が求められます。すべてのプラットフォームにおいて、制限時間(多くのクローラーは1~5秒の応答ウィンドウ内で動作します)内に応答できないAIクローラーは、取得できないコンテンツをインデックスできないため、サーバーの応答時間はAI検索における直接的な可視化要因となります。
カテゴリー5:一貫性と網羅性
定期的かつ包括的なコンテンツの更新は、特に規制の厳しい分野や変化の激しい分野において、ブランドが情報をアクティブに管理しており、最新のソースとして信頼できるというシグナルをAIシステムに伝えます。関連するコンテンツクラスター全体で深いトピック網羅性を持つブランドは、孤立した高品質なページのみを持つブランドよりも一貫して高くランク付けされます。
V3調査における3つの新たな知見
2025年にあらたに重要であると特定された3つの要素は以下の通りです。
共起(Co-occurrence)が極めて重要に: LLMは引用先を決定する前に、複数のソースを相互参照する傾向を強めています。自社の強力なドメインを持っているだけでなく、権威あるドメイン全体で一貫して言及されることが、引用率を大幅に向上させます。
検証可能な主張が単なる断定を凌駕する: モデル(特にClaude)は、根拠のない主張を行うコンテンツの評価を下げます。査読済みの引用文献やデータに基づいたケーススタディを追加することで、トピカルオーソリティ(話題の権威性)のスコアに測定可能な改善が見られます。
モデルごとに重視する要素が異なる: ChatGPTは表面的なソーシャルシグナルを低く評価する一方で、オーセンティックなコミュニティでのプレゼンス(Redditのスレッドやフォーラムでの議論)を重視します。Claudeの二本柱は、コンテンツの関連性と信頼性です。Perplexityは鮮度(Freshness)の重み付けが最も高く、構造化データへの依存度が最も強くなっています。Grokは技術的パフォーマンスの重み付けが最大です。
AI SEO最適化チェックリスト:30のアクションアイテム
コンテンツの品質と明瞭性
- ターゲットオーディエンスがAIシステムに尋ねる可能性の高い特定の質問に対し、明確に回答しているか
- マーケティング的な装飾や専門用語を省き、自然で会話的な言語を使っているか
- 複雑な概念を例え話、類推、あるいは具体的なシナリオで説明しているか
- スキャンしやすさ(流し読みのしやすさ)を考慮し、短い段落、箇条書き、説明的な小見出しを使っているか
- 各セクションで、背景情報を述べる前にまず直接的な答えを提示しているか
事実の正確性と信頼性
- すべての重要な主張に対して、信頼できるリンク先ソースが提示されているか
- 統計データや参照文献は、過去12〜18ヶ月以内のものか
- 業界の一般的な前提を、最新のデータに基づいて事実確認しているか
- プロモーション目的の誇張や曖昧な一般化が含まれていないか
- 著者の資格や専門知識が明確に示されているか
構造とセマンティックな明瞭性
- コンテンツが明確なトピック階層(H1→H2→H3)で整理されているか
- 必要に応じてFAQセクション、定義、ステップバイステップの手順が含まれているか
- スキーママークアップ(FAQPage, HowTo, Article, Organization)が実装されているか
- セマンティックな用語や関連エンティティが全体を通して自然に使われているか
- 主要なエンティティ名(ブランド名、製品名、カテゴリ名)が一貫して使用されているか
AI可視化のための技術的シグナル
- 主要なAIクローラーに対してrobots.txtでブロックされておらず、インデックス可能かつクロール可能か
- 重要なコンテンツが最初のHTMLレスポンスで提供されているか(JavaScript依存がないか)
- ページタイトルとメタディスクリプションが明確で正確、かつ検索意図と一致しているか
- マルチモーダルAIツールをサポートするため、すべての画像に説明的なaltテキストが設定されているか
- サーバー応答時間が2秒未満になるよう、ページ速度が最適化されているか
LLMの発見とモニタリング
- 主要なAIツール(Perplexity, ChatGPT, Gemini)で、ブランドがどのように言及されているかをテストしているか
- AI可視化プラットフォームを使用して、ブランドへの言及や引用を監視しているか
- ブランド名クエリやロングテールの会話型クエリを追跡し、最適化しているか
- サーバーログでAIクローラーのアクティビティを監視しているか
ソーシャルと引用のプレゼンス
- カテゴリにとって最も重要なAIモデルに供給源となるソーシャルプラットフォームでコンテンツを公開しているか:
- RedditとLinkedIn(主要な10のAIサーフェスすべてで引用される)
- YouTube(GoogleのAIサーフェス:AI Overviews, Gemini, AI Mode向け)
- X (Twitter)(特にGrok向け)
- ソーシャルコンテンツで、公開された安定したURL、明確なエンティティ言語、回答ファースト形式を使用しているか
- 権威ある引用を獲得するために、オリジナルの調査、データ、ケーススタディを公開しているか
AI検索での可視性を測定する方法
SERP(検索結果ページ)での順位を正確に追跡できる従来のSEOとは異なり、AIにおける可視性の測定には、従来の分析ツールではサポートされていない多次元的なアプローチが必要です。
指標1:AIによる言及と引用
関連するクエリに対するAIの回答で、ブランドがどの程度言及されているかを追跡します。また、「言及(ブランド名が表示される)」と「引用(ブランドへのリンクがある、またはソースとして直接帰属される)」を区別してください。引用はより強力な権威性のシグナルです。これは、AIシステムがあなたのコンテンツを多くの参照先の一つとしてではなく、主要なソースとして扱っていることを意味します。
ChatGPT、Gemini、Perplexityで業界関連のクエリを用いて定期的に手動テストを行うことで、方向性を示すデータが得られます。体系的な追跡を行うには、専用のAI可視化プラットフォームが必要です。
指標2:ブランドクエリのモニタリング
ユーザーが比較クエリや推奨クエリ(「[製品カテゴリ]のベストは?」「[貴社ブランド]と[競合他社]の比較は?」「[特定のユースケース]において[貴社ブランド]は良い選択肢か?」など)を検索する際、ブランドがどのように表示されるかを監視しましょう。これらのクエリは、AIによる引用が直接的にブランドの検討や購買決定につながるハイインテント(高意欲)なモーメントを表しています。
指標3:インクルージョン率とシェア・オブ・ボイス(SOV)
インクルージョン率は、トラッキング対象のAIクエリのうち、貴社ブランドが言及された割合を測定します。シェア・オブ・ボイスは、カテゴリ内のAI引用全体における貴社への言及割合を競合他社と比較して追跡します。これらの指標は、有意義なトレンドデータを生成するために、一貫したクエリセットを用いて継続的に測定する必要があります。
指標4:正確性とセンチメント
AIシステムが貴社ブランドを「言及しているか」と、「適切に説明しているか」は別個の指標です。価格の誤り、製品機能の不正確さ、時代遅れのポジショニングなど、AIによる不正確な説明は、単に検索結果に表示されないことよりも検知や修正が困難な「ブランドセーフティ」上の問題となります。センチメント(ポジティブ、ニュートラル、ネガティブなフレーミング)と正確性(AIのブランド説明における事実の正確さ)は、インクルージョン率とは別に追跡する必要があります。
Dageno AI:AI SEOを測定可能かつ実行可能なものにするプラットフォーム

専用の測定・最適化プラットフォームなしでAI SEO戦略を実行することは、分析ツールなしでリスティング広告を運用するようなものです。最適化の判断がデータではなく直感に頼ることになり、改善の検証が不可能になるためです。Dageno AIは、AI SEOを体系的でデータ駆動型のプラクティスへと昇華させる包括的なインテリジェンス層を提供します。
Dageno AIは、ChatGPT、Perplexity、Gemini、Google AI Mode、AI Overviews、Claude、Grok、Copilot、Llama全体におけるブランドの言及、シェア・オブ・ボイス、センチメント、ポジショニングの正確性をリアルタイムで監視します。同プラットフォームの「セマンティック・ギャップ分析」は、単なる監視にとどまりません。AIシステムがブランドのオーソリティを過小評価する原因となっている特定のコンテンツ構造、エンティティ関係、トピックの網羅性の欠如を特定します。さらに、GEOコンテンツ・オプティマイザーが、ターゲットを絞ったコンテンツ更新、スキーマの改善、配信戦略を通じて、これらのギャップを埋めるための構造化された推奨事項を生成します。
Dageno AIのAI Search Analyzerブラウザ拡張機能は、この機能をコンテンツワークフローにまで拡張し、エンジニアのリソースを必要とせずに、個々のページの「AI検索レディネス(スキーマ検証、クロール可能性シグナル、見出し構造、コンテンツ品質指標など)」を監査できるようにします。ナレッジグラフへの注入機能は、ブランドのエンティティ定義や製品カテゴリの紐付けをAI Overviewsや対話型AIの回答に正確に反映させる手法として、多くのチームから高く評価されています。
従来のSEOパフォーマンスとAI検索での可視性の両方を追跡するブランドにとって、Dageno AIの「競合引用ベンチマーク」機能は、主要プラットフォームやクエリカテゴリごとにAI引用率が競合他社とどのように異なるかを明確に示します。これにより、反応的(リアクティブ)ではなく戦略的な最適化の意思決定が可能になります。無料プランも用意されており、AI SEO成熟度のどの段階にあるチームでもDageno AIを利用可能です。
Dageno AIのAI SEOインテリジェンスを調べる →
AI検索で優位に立つ準備はできていますか?
今すぐ始める(無料) >AI検索基盤としてのソーシャルプラットフォーム
現在のAI SEOにおいて最も重要かつ過小評価されている変化の一つは、AIの検索(リトリーバル)におけるソーシャルメディアコンテンツの役割です。10のAIサーフェスにおける610万件のAI引用を分析したところ、ソーシャルメディアはAIの回答における最も急速に成長しているエビデンス層の一つとなっており、2025年9月から11月の間に引用件数全体よりも4倍の速さで増加していることが判明しました。
ソーシャルプラットフォームとAIモデルの関係は、所有権とライセンスアクセスの明確なパターンに従っており、研究者はこれを**「プラットフォーム結合(Platform Coupling)」**と呼んでいます。
- RedditとLinkedInは、研究対象となった10すべてのAIモデルで引用されており、広範なAI露出を必要とするブランドにとって唯一のユニバーサルな基盤となっています。
- YouTubeは、GoogleのAIサーフェス(AI Overviews、Gemini、AIモード)における主要なソーシャルサイテーションソースであり、データセット内のYouTubeサイテーションの82.5%を占めています。
- **X (Twitter)**は、ほぼ例外なくGrokのソースとなっています(Xのサイテーションの99.7%がGrokによるもの)。これはxAIが直接所有していることによる直接的な結果です。
AI SEO戦略における実用的な意味合い:ソーシャルメディアを単なる拡散チャネルとしてではなく、AIモデルが情報を取得するための「リトリーバル・インフラ(検索・取得基盤)」の一部として扱うべきです。安定したパブリックURL、明確なエンティティ言語、回答ファースト構造を備えた引用可能なコンテンツを、ターゲットとするAIサーフェスに供給されるプラットフォーム上で公開することは、サイテーション(引用)効果を測定できる直接的なAI SEOのレバーとなります。
AI SEOの未来:エージェントコマースと次の段階
この状況には明確な3つのフェーズがあり、それぞれが異なる成熟度で既に運用されています。
検索を必要としない「検索レス」な発見は既に始まっています。 OSやブラウザ、アプリに組み込まれたLLMは、ユーザーが従来のような検索を行う前に、ユーザーのクエリに回答しています。これにより、AIでのプレゼンスはオプションではなく、前提条件となっています。
AIファーストのコンテンツフォーマットが現在の標準です。 AI検索で最も目立つブランドは、スキーマが充実した、構造化された事実ベースのコンテンツを体系的に構築しています。今、問われているのは「重要かどうか」ではなく、「いかに大規模に実行するか」です。
「エージェントコマース」が次のフロンティアです。 AIエージェントは、人間が最終段階で意思決定を行うことなく、ユーザーに代わってブラウジング、比較、決済完了を行うようになりつつあります。製品カタログを持つブランドにとって、正確な価格、在庫状況、仕様を備えた状態でエージェントによる製品発見に正しく表示されることは、今すぐ備えるべきAI SEOのフロンティアです。
現在、コンテンツオーソリティの構築、技術的なクロール可能性(Crawlability)、セマンティックな明瞭性、そしてクロスプラットフォームでのサイテーションプレゼンスを体系的にAI SEOに投資しているブランドこそが、既に展開し加速しつつある検索環境において、可視性の基盤を構築しているのです。
よくある質問
リトリーバルベースのモデルと静的なAIモデルの違いは何ですか?
静的なLLMは固定された学習データに依存しており、リアルタイムで新しい情報を取得することはありません。一方、リトリーバルベースのモデル(Perplexityやブラウジング機能付きChatGPTなど)は、ライブのWebコンテンツを取得して回答するため、より新しいコンテンツを提示でき、迅速な最適化への対応が可能です。
AI向けに最適化する場合でも、従来のSEOは必要ですか?
はい、断言できます。AI SEOは従来のSEOの上に成り立っています。強力なクロール可能性、ドメインオーソリティ、高品質なコンテンツ、そして強固なテクニカルな基盤は不可欠です。なぜなら、AIシステムは従来の検索でパフォーマンスが高いページを頻繁に引用するからです。変わったのは、従来型の検索で上位にランクインすることが「必要条件ではあるが、十分条件ではなくなった」という点です。
AI SEOは従来のSEOに取って代わるのですか?
いいえ。両者は補完関係にあります。SEOは、AIシステムがコンテンツを発見・評価するために必要なオーソリティとクロール可能性を構築します。AI SEOは、そのページからコンテンツが抽出され、AIの回答内に配置されるようにするための、構造化されたセマンティックで豊かな「質問回答レイヤー」を付加するものです。
AI SEOの最適化で結果が出るまでどのくらいかかりますか?
AIの可視性の変化は、通常、実装から4〜12週間のラグが生じます。これは、ターゲットとするAIプラットフォームがどの程度頻繁にリトリーバルシステムを更新するか、また、あなたのコンテンツがどの程度頻繁に再クロールされるかに依存します。Perplexityのようなリアルタイムの取得能力が高いプラットフォームは、より迅速に変更を反映させることができます。学習データに基づく改善にはさらに時間がかかります。これは、モデルのアップデートが自身の制御外のスケジュールで行われるためです。
参考文献
About the Author

更新者
Tim
Tim is the co-founder of Dageno and a serial AI SaaS entrepreneur, focused on data-driven growth systems. He has led multiple AI SaaS products from early concept to production, with hands-on experience across product strategy, data pipelines, and AI-powered search optimization. At Dageno, Tim works on building practical GEO and AI visibility solutions that help brands understand how generative models retrieve, rank, and cite information across modern search and discovery platforms.
