GSC/GA4から最適化タスクへ:コンテンツ成長診断システムの構築方法
GSC、GA4、ブランド知識、AIリファラル、クローラーデータを活用し、コンテンツ最適化タスクへと変換するための実践的なフレームワーク。
AI 検索の可視性を追跡するインストールなし
更新者
10 最小読み取り
Jun 26, 2026に更新されました
近年、コンテンツ運用におけるひとつの転換がますます鮮明になっています。それは、**「トラフィック志向(Traffic Mindset)」から「グロース志向(Growth Mindset)」**への移行です。
AI検索やコンテンツ配信が複雑化する中、SEOを実施し、記事を公開し、インプレッションやクリックを追跡するだけではもはや十分ではありません。現代のコンテンツチームには、ユーザーの全ジャーニー(ユーザーがどのように到達し、なぜ滞在し、なぜコンバージョンに至らず、どのステップで最適化が必要か)を理解することが求められています。
言い換えれば、コンテンツ担当者の役割は、単なる**「コンテンツ実行者」から、「成長システムの参加者、ひいては設計者」**へと徐々に進化しています。
これは、私がコンテンツグロースのプロジェクトに取り組む中で痛感していることです。
インプレッション、クリック、検索順位、インデックス状況、記事数といった指標も重要ですが、成果を真に導くのは「サイトのコンテンツ量」ではありません。「既存のコンテンツが、検索需要とビジネスアクションをいかに統合できているか」が鍵となります。
これはB2B SaaS、独立系Webサイト、Eコマース、そして製造業のWebサイトにおいて特に顕著です。多くのページは、トラフィックがゼロなわけではありません。ユーザーは検索経由で流入するものの、そこからファネルの奥へ進まないのです。検索意図とページ内容がうまく噛み合っておらず、記事を読んでもCTA(Call to Action)に気づかず、CTAをクリックしても重要イベント(コンバージョン)に到達していません。
問題はデータ不足ではなく、以下のような「意思決定の連鎖」が欠如している点にあります。
検索需要 → ページ検索意図とのマッチング → ユーザー行動 → ビジネスアクション → 最適化タスク → パフォーマンスのフィードバック
この課題を解決するため、私たちは独自のコンテンツグロース診断システムを構築し、Eコマース、製造業、コンシューマー家電、AI SaaSなど、複数の独立したWebサイトで検証を重ねてきました。
このシステムは、単なるSEOレポートではありません。また、AIに一般的な最適化の提案を求めるだけのツールでもありません。GSC(Google Search Console)、GA4、ブランドナレッジベース、AIリファラル、AIクローラーログを統合し、ページ単位の診断ワークフローを実現するものです。
このシステムにより、チームは以下の問いに明確な回答を得られます。
- どのクエリと意図がユーザーをページに誘導しているのか?
- そのページは意図を正しく満たせているか?
- ページ到達後、ユーザーは記事を読み、CTAを認識し、クリックしているか?
- ページ内の製品情報は正確か?
- AI製品は訪問をもたらしているか、またAIクローラーはアクセスできているか?
- これらのエビデンスをどのように実行可能な最適化タスクに変換するか?
- ページ更新後、どの指標を追跡すべきか?
全体的なデータの流れは以下の通りです。
まず、データを統合します。次に、異なるソースからのデータを同一のURLに紐付けます。クエリクラスターを使用して検索意図を特定し、ページDOM(Document Object Model)分析を行い、コンテンツがその意図を満たしているかを判定します。さらに、GSCとGA4のファネルデータを組み合わせてユーザーの離脱地点を特定し、ブランドナレッジベースで事実確認を行います。AI/GEO(生成エンジン最適化)シグナルを用いて、AIによる紹介トラフィック(AI Referral Traffic)とクローラーのアクセス性を評価します。最終的に、すべてのエビデンスを実行可能な最適化タスクへと変換し、更新後のパフォーマンスを継続的にトラッキングします。
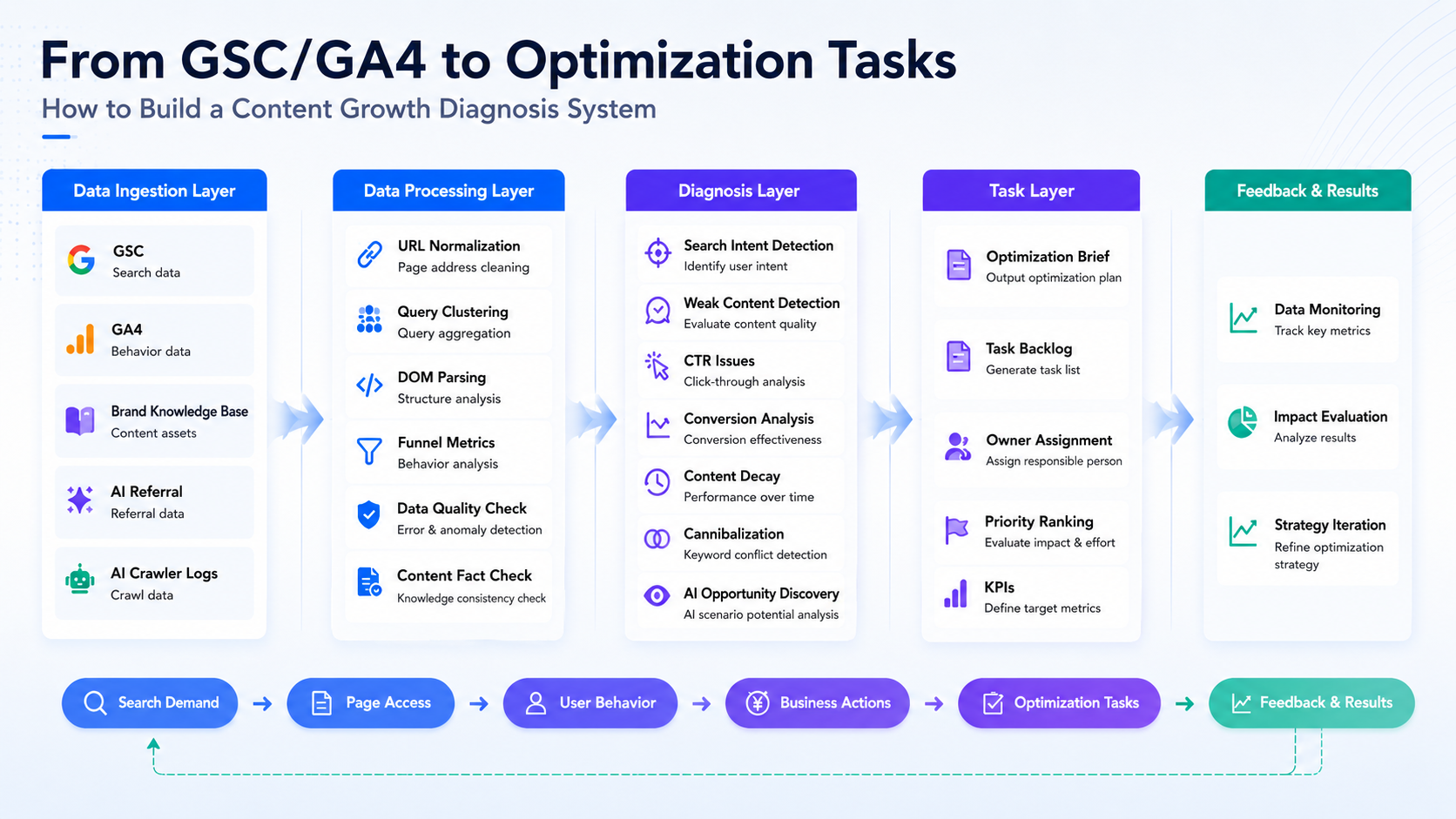
以下に、ワークフローの詳細を解説します。
1. データインジェクション:検索、行動、事実、AIシグナルをひとつのチェーンにする
最初のレイヤーはデータ取り込みです。主に5種類のデータを接続します。
- Google Search Console (GSC)
- Google Analytics 4 (GA4)
- ブランドナレッジベース
- AIリファラルセッション
- AIクローラーログ
1.1 GSCとGA4
GSCは検索面のパフォーマンスを担います。インプレッション、クリック、CTR、平均掲載順位、および詳細なクエリレベルのパフォーマンスを提供します。
GSCを通じて、どのクエリがユーザーの流入に寄与しているか、またインプレッションはあるもののクリック率が低下し始めているページを特定できます。
GA4はサイト内のユーザー行動を担います。検索経由のランディングセッション、エンゲージメント率、スクロール行動、CTAインプレッション、CTAクリック数、サインアップや重要イベントなどを提供します。
GA4を通じて、ユーザーがページ到達後に読み進めているか、製品エントリーポイントを視認しているか、CTAをクリックしているか、そしてビジネス上重要なアクションに至っているかを判定できます。
GSCとGA4の真価は、両者を組み合わせたときに発揮されます。
GSCだけでは検索結果内での出来事しか見えず、GA4だけでは流入後の挙動しか見えません。両者を接続することで、記事のどこでボトルネックが発生しているのかを正確に特定できます。
例:
-
インプレッションは高いがCTRが低い
タイトル、メタディスクリプション、検索結果との関連性を優先的に改善する。 -
クリック数は多いがエンゲージメントが低い
導入部、目次、ページ構造、コンテンツと検索意図の一致度を優先的に改善する。 -
エンゲージメントは良好だがCTAクリックが少ない
製品モジュール、CTAのコピー、CTAの配置を優先的に改善する。 -
CTAのクリックは発生しているが、コンバージョン(主要イベント)に至っていない
登録フロー、デモ申し込みフロー、またはランディングページの遷移先を確認してください。
1.2 ブランドナレッジベース
ブランドナレッジベースは、製品情報の真実性を検証する役割を担います。
チームは最新の製品機能、料金プラン、スクリーンショット、ブランドメッセージ、競合比較基準、FAQ回答、重要な製品アップデートなどをナレッジベースに同期させることができます。
システムはページコンテンツとナレッジベースを照合し、記事内の製品情報が陳腐化していないかを判断します。
このモジュールの目的は、LLMに対して最新かつ統一された、信頼できる製品情報のソースを提供することです。
ブランドナレッジベースがない場合、システムは公開日、時間的な言及、スクリーンショット、またはSERPの鮮度に基づいてコンテンツが古い可能性があると推測することしかできません。ナレッジベースと連携することで、システムは以下のようなより具体的な改善タスクを生成できます。
- 古い製品スクリーンショットの差し替え
- 料金プラン説明の修正
- 競合比較表の書き換え
- 最新のFAQ回答の同期
1.3 AIリファラルとAIクローラーログ
AI/GEOデータは、以下の2つのカテゴリーに分類されます。
- AIリファラルセッション
- AIクローラーログ
AIリファラルセッションはGA4から取得されます。これらはChatGPTやPerplexityのような製品がWebサイトに実際のトラフィックをもたらしているか、そしてそのトラフィックがエンゲージメントやコンバージョンを生んでいるかを示します。
AIクローラーログは、サーバーログ、Cloudflare、CDNログ、またはエッジログから取得されます。これらはGPTBot、PerplexityBot、ClaudeBotなどのクローラーがページにアクセスしたかどうか、ステータスコードが正常か、またrobots.txt、WAF、CDN設定、ログ欠損などによってアクセスが阻害されていないかを示します。
この区別は重要です。
AIクローラーはGA4のトラフィックソースではありません。
GA4はAI製品からのリファラルセッションを測定するのに適しています。クローラーのアクセスはログを通じて確認する必要があります。
あるページがGPTBotにクロールされていても、ChatGPTからのリファラルセッションがゼロである場合があります。逆に、Perplexityからのリファラル流入が既に発生しているページでも、クローラーログが不完全な場合があります。両方の信号を併せてレビューすることで初めて、チームは「引用可能なコンテンツを増やすべきか」あるいは「技術的なアクセスビリティを先に解決すべきか」を判断できます。
2. データ処理:URLの統合、そしてページレベルにおけるエビデンスの構築
データが接続された後、システムはすぐに提案を生成するわけではありません。まずはデータの処理を行います。
処理レイヤーの目的は、断片的なデータをページレベルのエビデンス(証拠)に変換することです。
2.1 URLレベルのデータ統合
最初のステップはURLの正規化です。
GSC、GA4、サーバーログでは、同じページのURLが異なる形式で記録されることがよくあります。
例えば、同じ記事であっても、GSCではフルURLで記録され、GA4ではトラッキングパラメータ付きで記録され、サーバーログではパスのみで記録されるといったケースです。システムがこれらのアドレスを事前に標準化しなければ、同じ記事が複数のレコードに分割されてしまいます。検索クリックは一方に、オンサイトセッションは他方に、CTAクリックはまた別の場所に、クローラーアクセスはさらに別の場所に分散してしまいます。
そのため、システムはUTMパラメータ、広告クリック用パラメータ、ページアンカーなど、コンテンツそのものに影響を与えない要素を除去してページアドレスを精査します。その後、同一の記事を1つの正規URL(Canonical URL)にマッピングします。
このステップを経て初めて、インプレッション、クリック、セッション、CTA、コンバージョン、AIクローラーログが、同一の記事に対して正しく紐付けられます。
2.2 クエリクラスタリング
クエリクラスターとは、ユーザーの検索意図に基づいて類似した検索クエリをグループ化することを指します。
GSCには大量の断片的なクエリが含まれています。コンテンツチームがこれらのクエリを1つずつ確認していたのでは、ユーザーが実際に何を目的としているのかを理解するのは困難です。
システムは検索意図に基づいてクエリをグループ化し、以下のようなインテントタイプをラベル付けします。
- 定義意図(Definition)
- ツール選定意図(Tool-selection)
- 比較意図(Comparison)
- コマーシャル意図(Commercial)
- 料金意図(Pricing)
- サポート意図(Support)
- ナビゲーション意図(Navigational)
将来的には、これらをAIマーケティングやAI検索シナリオにおけるユーザーインテントにマッピングすることも可能です。
これにより、チームの視点は何千もの散らばったキーワードから、より少数の「ユーザーニーズの集合」へと変化します。
また、この機能の境界線を明確にすることも重要です。
これはクエリとコンバージョンを精密に紐付けるアトリビューション(貢献度計測)ではありません。
システムは「特定のクエリが、特定のサインアップを直接引き起こした」と断定するわけではありません。その代わり、検索意図とコンテンツの適合性という問題を解決します。つまり、「どのユーザーのニーズがユーザーをページに誘導し、そのページにはそのニーズに応えるコンテンツが存在するか」を明確にするのです。
2.3 ページDOM解析
第3のステップはページDOM解析です。
システムは以下のページ構造をクロール・解析します。
- タイトル
- H1
- H2
- H3
- FAQセクション
- テーブル
- CTA
- 内部リンク
- 本文コンテンツの断片
その後、各クエリクラスターに対応するコンテンツ箇所がページ内に存在するかどうかを判定します。
例えば、ユーザーがツール比較クエリで検索しているにもかかわらず、ページが概念の解説に終始し、ツール選定基準や比較表、活用事例が存在しない場合、システムは意図との適合性が低い(weak intent matching)と判断します。
2.4 データ品質評価
すべてのデータが自動タスク生成に適しているわけではありません。
システムは以下の項目もチェックします。
- GSCデータが欠落していないか
- GA4データが欠落していないか
- URLが正しくマッチングされているか
- サンプルサイズは十分か
- イベントトラッキングが完了しているか
- ブランド知識ベースが利用可能か
- AIクローラーのログが接続されているか
データの品質は、システムが実行を許可されるアクションを直接左右します。
| データ品質 | システムの挙動 |
|---|---|
| 高 | タスクのドラフトを生成する |
| 中 | 手動確認を経てのみタスクを生成する |
| 低 | 自動タスク生成を行わず、診断結果のみを表示する |
| 無効 | 判断やタスク生成を行わない |
このステップは非常に重要です。
コンテンツ診断システムは、ただ推奨アクションを生成する方法を知っているだけでは不十分です。根拠が不十分な場合や自動化すべきでない状況も的確に判断できなければなりません。
3. 診断ループ:検索ニーズからページ適合、ユーザー行動、ビジネスアクションまで
データ処理が完了すると、システムは診断レイヤーに入ります。
3.1 検索側:どのクエリとインテントがユーザーを流入させているか?
システムはまずGSCのクエリおよびクエリクラスターをレビューします。
同一の「AI可視化(AI visibility)」に関連するページであっても、ユーザーインテントは大きく異なる場合があります。
- 「AI可視化とは何か」は概念の理解を示します。
- 「SaaS向けAI可視化ツールのベスト選定」はツールの選定を示します。
- 「GEOモニタリングプラットフォームの比較」はソリューションの比較を示します。
- 「ChatGPTでブランドへの言及を追跡する方法」は特定のワークフローを示します。
ページが以前は主に定義ベースのクエリを対象としていたにもかかわらず、新たにツール選定、比較、またはワークフロークエリからのインプレッションが発生している場合、システムはユーザーの需要(Demand)が変化したと識別します。
このステップは、以下の問いに答えます。
ユーザーはページに流入した際、何を達成しようとしているのか?
3.2 ページ側:ページはユーザーの検索意図(Search Intent)に適合しているか?
クエリクラスターが特定された後、システムはページのDOMを解析します。
インテントの種類に応じて、求められるコンテンツ構造は異なります。
| インテントタイプ | 必要なコンテンツ |
|---|---|
| 定義インテント | 明確な定義、解説、FAQ |
| ツール選定インテント | ツールリスト、選定基準、活用事例、CTA |
| 比較インテント | 比較表、価格、相違点、活用事例 |
| ワークフローインテント | 手順、指標、テンプレート、よくある間違い |
| 商業インテント | 製品モジュール、事例研究、CTA、ネクストステップへの導線 |
システムは、これらの要素がタイトル、H1、H2、FAQ、テーブル、CTAに含まれているか、あるいは完全に欠落しているかをチェックします。
特定のクエリクラスターに検索インプレッションがあるにもかかわらず、ページの内容がそのニーズを浅くしかカバーしていない場合、システムはそれをコンテンツギャップ、新しいクエリの機会、または検索意図との適合性が低い状態(weak search intent matching)としてマーキングします。
このステップは、以下の問いに答えます。
ページはユーザーのニーズを適切に受け止め、満たしているか?
3.3 行動側:ユーザーはコンテンツを読み、CTAを目にし、クリックしているか?
コンテンツの適合性だけでは不十分です。ユーザーが実際にアクションを継続しているか検証するために、GA4の行動データが必要です。
システムは、検索露出からビジネスアクションに至るまでのページファネルを構築します。
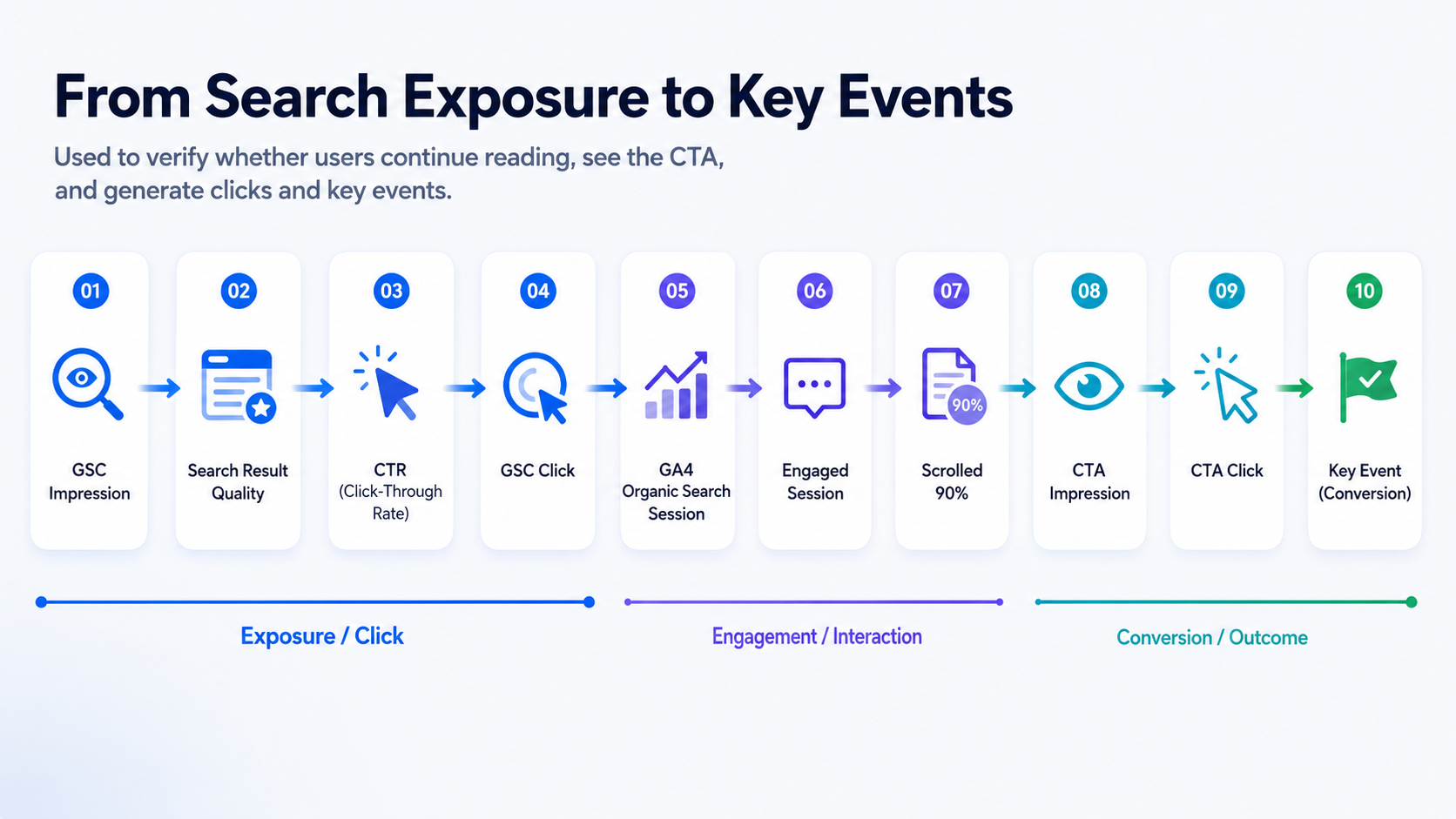
これはユーザーの離脱地点を特定するのに役立つため、診断プロセスにおいて最も重要な視点の一つです。
例:
- ユーザーがページに流入しているにもかかわらずエンゲージメントが低い場合、問題は導入部、目次、コンテンツ構造、またはページ読み込み体験にある可能性があります。
- ユーザーがページを読んでいるのにCTAのインプレッションが低い場合、CTAの配置場所が深すぎる可能性があります。
- CTAのインプレッションは正常だがクリックが低い場合、CTAのコピー、製品モジュール、またはユーザーインテントとの不一致が考えられます。
- CTAクリックはあるが、サインアップやデモの予約、主要なイベントへのコンバージョンが低い場合、問題は後続の登録プロセス、デモフロー、またはランディングページの導線にある可能性があります。
このステップは、以下の問いに答えます。
ユーザーは「閲覧」「CTA露出」「CTAクリック」「ビジネスコンバージョン」のどの段階でつまずいているか?
3.4 事実側:コンテンツは陳腐化しておらず、製品情報は正確か?
B2B SaaSのコンテンツにおいて、古いコンテンツとは単に公開日の問題ではありません。
昨年公開された記事でも正確であることはありますが、先月更新されたばかりの記事であっても、価格設定、機能、スクリーンショット、または競合比較がすでに誤っている可能性があります。
ブランド知識ベースは、ページコンテンツと最新の製品事実(Facts)を照合します。システムは以下をチェックします。
- ページで言及されている機能が現在も存在するか
- 価格設定は最新か
- スクリーンショットが古くなっていないか
- 競合比較が現在の基準に基づいているか
- FAQの回答が公式の見解と一致しているか
このモジュールは、以下の2つの一般的な問題を防ぎます。
- 古い記事がユーザーに誤った製品情報を伝え続けること。
- LLMが古いページコンテンツに基づいて誤解を招く推奨事項を生成すること。
このステップは、以下の問いに答えます。
システムの推奨事項は、最新の製品ファクトに基づいていますか?
3.5 AI/GEOサイド:AIソースはページにアクセスし、引用可能か?
AI/GEOモジュールは、主に2つの判断を下します。
第一に、AIリファラルセッションにより、AI製品が実質的な訪問をもたらしているかどうかを可視化します。例えば、システムはChatGPTやPerplexityなどのソースからセッションが発生しているか、それらのセッションがエンゲージメントや主要イベント(コンバージョン等)を生成しているかを確認します。
第二に、AIクローラーログにより、AIクローラーがページにアクセス可能かを確認します。システムはGPTBot、PerplexityBot、ClaudeBotなどのクローラーがページを訪問したか、レスポンスコード(200、304、403、404)がどうであったか、ブロックの原因があるか、ログの欠落がないかをチェックします。
これら2つのシグナルを組み合わせて、次のアクションを決定します。
- ページにAIリファラルはあるがコンバージョンが弱い場合:コンテンツの適合性とCTA(行動喚起)の最適化を優先します。
- クローラーのステータスに異常がある場合:robots.txtルール、WAF、CDN、またはログ統合のチェックを優先します。
- クローラーのアクセスは正常だが、ページに明確な定義、手順、FAQ、回答形式の要約が欠けている場合:引用可能なコンテンツの作成を優先します。
- AIリファラルは増加しているが主要イベントが弱い場合:AIトラフィックは存在するため、ビジネス側のページマッチングを改善する必要があります。
このステップによって、次の問いに回答します。
AI検索およびLLM引用のシナリオにおいて、問題はトラフィックか、コンテンツか、それとも技術的な可視性(Technical Visibility)か?
4. 課題タイプの特定:診断結果を運用キューへ変換する
上記の診断ステップを完了した後、システムは各ページを特定の課題タイプに割り当てます。
課題をグルーピングすることの価値は、コンテンツの最適化を単発の編集作業ではなく、バッチ処理(一括処理)として捉えられる点にあります。
一般的な課題グループには以下が含まれます:
- トラフィックの減少
- CTR(クリック率)の低下
- コンテンツの脆弱性、または検索意図(Search Intent)との不一致
- 古い、または時代遅れのコンテンツ
- コンバージョン率の低迷
- 重複、または競合するページ
- コンテンツ機会の欠落
- 技術的またはデータ上の問題
- GEO(生成AI最適化)またはAIの可視性の問題
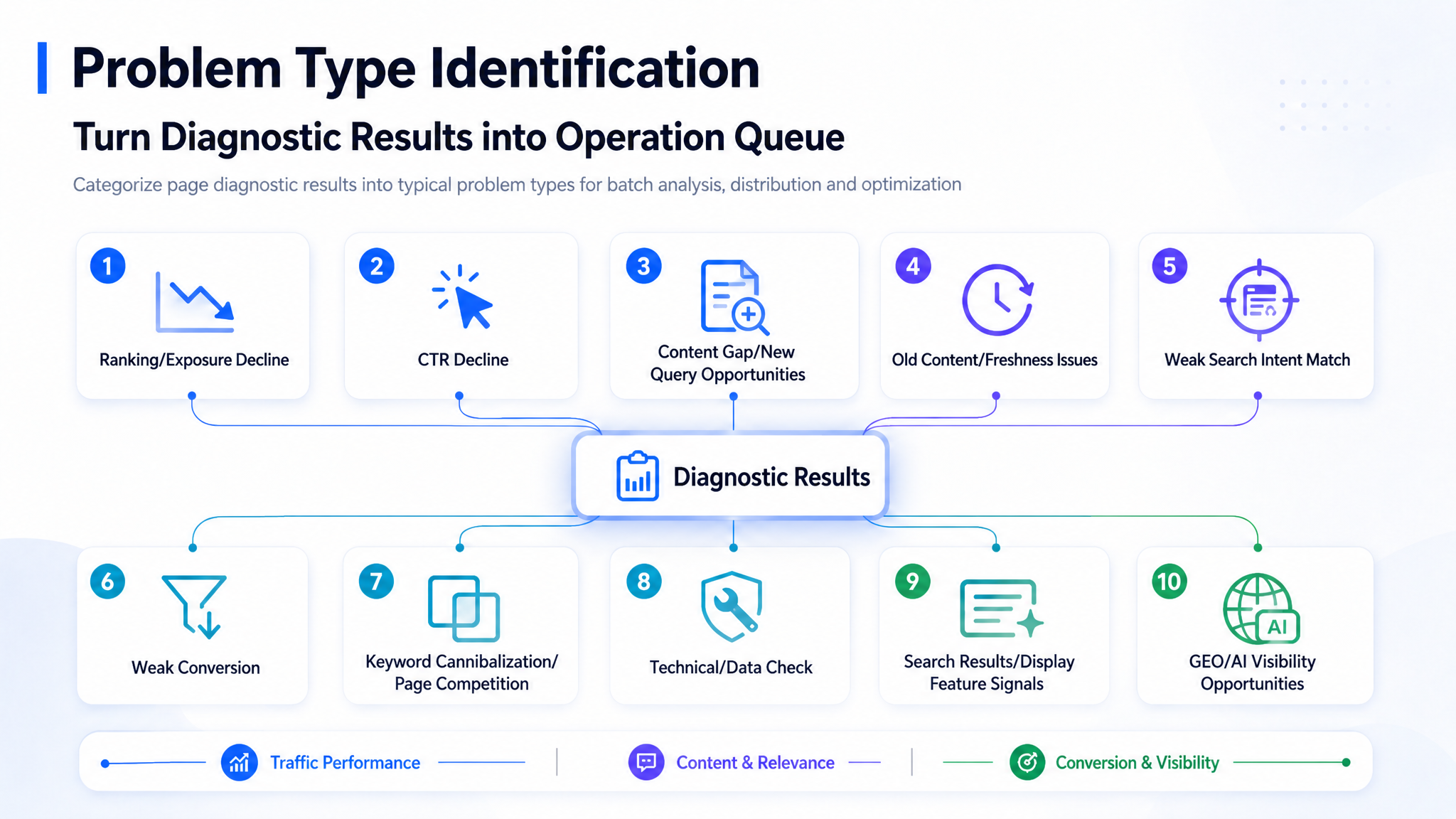
ページグループには、課題名だけでなく以下の情報も表示されます:
- トリガーとなった根拠
- ページファネルのスナップショット
- 主な影響を受けているクエリクラスター
- コンテンツの配置箇所
- データの品質
- 推奨されるアクションの要約
- 所有者(オーナー)
- ステータス
これにより、コンテンツオーナーは毎週、課題グループごとにタスクを管理できます。
例えば:
- 今週:CTR低下への対応
- 来週:コンバージョン率低下への対応
- その翌週:古いコンテンツやページカニバリゼーション(共食い)への対応
チームは、「何となく問題がありそうなページ」をランダムに編集するのではなく、課題タイプと優先度に基づいた最適化タスクを遂行できるようになります。
5. タスク生成:システムが最適化の推奨事項を出力
ページグループはフィルタリングのために使用され、単一ページの診断はタスク生成のために使用されます。
単一ページの診断ビューに入ると、システムは記事に関するすべての証拠を1つのページに集約します:
- ページファネル
- クエリクラスター
- コンテンツマッチング位置
- GA4のページ行動データ
- ブランドナレッジベースの検証結果
- データの品質
- 推奨されるアクション
推奨されるアクションは、主に以下の情報の組み合わせによって決定されます:
text
課題タイプのルール
+ クエリクラスター
+ ページ内のコンテンツマッチング位置
+ GA4のページパフォーマンス
+ ブランドナレッジベースの検証
+ AI/GEOシグナル
+ データの品質
その出力結果は、「記事を最適化する」といった曖昧な提案ではありません。明確に定義された以下の項目を含むタスクとなります:
- なぜこのページを更新する必要があるのか
- ページのどの箇所に問題があるのか
- 具体的にどう変更すべきか
- 誰が責任者か
- 更新後にどの指標をチェックすべきか
6. 事例:フル診断チェーンがどのようにページに適用されるか
次のページを例に挙げます:
https://dageno.ai/en/blog/top-tools-to-track-ai-mentions-in-llms
ステップ1:GSC(Search Console)で検索需要を発見
GSCによると、このページは「AIメンション追跡ツール(AI mention tracking tools)」に関連するクエリからのインプレッションを獲得し始めています。
GSCだけを見ると検索需要があることはわかりますが、そのページがその需要を十分に満たしているかどうかを判断することはできません。
ステップ2:クエリクラスターで「ツール選定意図」を特定
システムは、これらのクエリを「ツール選定意図」のクラスターに分類します。
これは、ユーザーが単に概念を理解しようとしているのではなく、特定のカテゴリーのツールを探しており、機能の比較を行っている可能性が高く、場合によっては試用や購入のプロセスを開始する準備ができていることを意味します。
ステップ3:DOM解析で意図との不一致を確認
システムがページのDOM(ドキュメント構造)を解析したところ、導入部分やH2構造が主に概念の解説に終始していることが判明しました。
ページ内には、明確なツール選定基準、比較ディメンション、あるいは具体的ユースケースが提供されていません。
換言すれば、検索側では「ツール選定」へ意図がシフトしているのに対し、ページは依然として「概念解説記事」のように振る舞っている状態です。
ステップ 4: GA4による行動エビデンスの追加
GA4のデータによると、該当ページはエンゲージメント率が比較的高いものの、CTAのクリック率が低いことがわかります。
これは、ユーザーは読み進めているものの、ページが製品のアクションへとスムーズに誘導できていないことを示唆しています。
ステップ 5: ブランドナレッジベースによる製品情報の検証
ブランドナレッジベースでは、ページ内の製品スクリーンショットが古くなっていること、および一部の機能説明が最新バージョンに更新されていないことが確認されました。
これが修正されない場合、LLMが最適化の推奨案を生成する際に、古い製品情報を使用し続けるリスクがあります。
ステップ 6: AIクローラーログによる技術的アクセシビリティの確認
AIクローラーのログを確認したところ、GPTBotは当該ページを正常にクロールできています。
つまり、優先すべき課題は技術的なクロール上の問題ではありません。より緊急性の高い課題は、「コンテンツが引用(シテーション)に適しているか」「製品情報が正確か」「CTAがツール選定フェーズのユーザーのニーズと合致しているか」という点です。
最終的なタスクドラフト
システムは以下のようなタスクドラフトを生成します。
markdown
ページ: /blog/top-tools-to-track-ai-mentions-in-llms
課題タイプ:
- 検索インテントとの適合性不足
- コンバージョン率の低迷
- コンテンツの陳腐化
トリガーとなるエビデンス:
- ツール選定クエリでの検索インプレッションが発生している
- 導入部やH2構成が依然として概念説明に偏っている
- エンゲージメントは高いが、CTAクリックが低い
- ブランドナレッジベースで古いスクリーンショットを検知
- GPTBotのクロールは正常
推奨アクション:
- ツール選定基準モジュールの追加
- ツール比較テーブルの追加
- 製品スクリーンショットの更新
- 汎用的なサインアップCTAを「AIメンション監視ソリューションを見る」へ変更
- FAQコンテンツの追加
- LLMが引用しやすいステップバイステップ形式のコンテンツを追加
更新後に追跡すべき指標:
- CTR(クリック率)
- オーガニック検索セッション数
- CTAクリック数
- デモ申し込み数
- 主要イベント(コンバージョン)
- AIリファラル経由のトラフィック
- クローラーのステータスこのようにして、記事は「データパフォーマンスが不明瞭」な状態から、具体的なタスクへと明確化されます。
チームは以下の項目を把握できるようになります:
- なぜその記事を変更する必要があるのか
- 問題はどこにあるのか
- 何を更新する必要があるのか
- 誰が担当すべきか
- その後、どの指標をレビューすべきか
7. パフォーマンスモニタリングとレビュー
真のコンテンツ成長ループを構築するには、記事の更新後、パフォーマンスデータをシステムにフィードバックする必要があります。
現在のバージョンでは、データ取り込みからページ診断、タスクドラフト生成までの一連のワークフローが実行可能です。
次の段階として、実行後のパフォーマンス追跡を追加し、各コンテンツの更新と、その後の指標の変化を紐付ける予定です。
システムは以下を記録します:
- タスク生成日時
- 更新されたモジュール
- リリース日時
- 担当者
- タスクステータス
- フォローアップのパフォーマンスデータ
これにより、チームは各最適化アクションが実際に成果を生んだかどうかを評価できます。
8. 今後構築すべき機能
現時点でもシステムの主要な診断フローは稼働していますが、さらなる改善が必要です。
8.1 クエリインテントのクラスタリング
現在のバージョンは、主にテキストの類似性とルールベースの判定に依存しています。垂直統合型の業界であれば、一般的なクエリの大部分をカバーできています。
しかし、ロングテールクエリ、新出用語、あるいは意味は近くてもインテント(検索意図)が異なるクエリについては、正しくグルーピングできない場合があります。
今後は、キーワードマッチングとLLMベースの判定を組み合わせることで、クエリクラスターをより正確に分類していく予定です。
確信度の低いインテントクラスターについては、システムが自動的に「手動確認が必要」とマークし、不十分なエビデンスに基づいて誤ったタスクが生成されるのを防ぎます。
8.2 ブランドナレッジベースの自動更新
現在のブランドナレッジベースは、主に手動インポートによって維持されています。これは、製品機能、価格設定、スクリーンショット、FAQ、競合との差別化メッセージなどのコア情報を一元管理する初期段階では有効です。
しかし、長期的には手動メンテナンスだけに頼ることはできません。
次のステップとして、製品の更新ログ(Changelog)、CMSデータ、または社内ドキュメントソースと連携し、製品の進化に合わせてナレッジベースが自動的に更新される仕組みを構築します。
これにより、古いコンテンツのチェックが手動レビューに依存しなくなります。また、システムは古い機能、古いスクリーンショット、誤った価格設定、現在のマーケティングメッセージと乖離した製品説明をより迅速に特定できるようになります。
8.3 パフォーマンス追跡
システムはすでに「どの記事を更新すべきか」「なぜ更新すべきか」「どこを変更すべきか」「エビデンスに基づくタスクをどう生成するか」を決定できます。
次のステップでは、タスク実行後のパフォーマンス追跡を追加し、各コンテンツの更新と、その後の指標の変化を紐付けます。
これが完了すれば、コンテンツチームは以下を理解できるようになります:
- 最適化が実際に成長を生んだか
- どのような種類の更新がより効果的か
- どのページがさらなる改善(イテレーション)を必要としているか
結論
このコンテンツ成長診断システムの目的は、単なるSEOレポートをもう一つ増やすことではありません。
その目的は、オーガニックトラフィックの最適化を、以下の要素を備えたプロセスへと変革することです。
- 実行可能(Executable)
- 追跡可能(Trackable)
- レビュー可能(Reviewable)
- ビジネス成果に直結(Connected to business outcomes)
このアプローチにより、検索データ、ページコンテンツ、ユーザー行動、ブランド情報、AI/GEO(生成エンジン最適化)上の可視性、最適化タスク、そしてパフォーマンスのフィードバックが一つのクローズドループとして統合されます。
結果として、コンテンツチームは「記事を最適化せよ」といった曖昧な指示を受けることはなくなります。
代わりに、以下の項目が明確に理解できるようになります。
- なぜそのページを変更する必要があるのか
- どこに問題があるのか
- 何を更新すべきか
- 誰がタスクを実行すべきか
- 更新後にどの指標をチェックすべきか
GitHub: github.com/dageno-ai/organic-content-intelligence
もしあなたが海外市場向けの独立したウェブサイトを構築しており、コンテンツの成長やAI検索に注力していて、このソリューションについて議論したり、システムの詳細な実装について知りたい場合は、WeChat: dudulhc までご連絡ください。
About the Author

更新者
Dageno

