De GSC/GA4 a tareas de optimización: Cómo construir un sistema de diagnóstico de crecimiento de contenido
Un marco práctico para convertir datos de GSC, GA4, conocimiento de marca, referencias de IA y rastreadores en tareas de optimización de contenido accionables.
Seguimiento de la visibilidad de búsqueda de IASin instalación
Actualizado por
10 lectura mínima
Actualizado el Jun 26, 2026
En los últimos años, un cambio se ha vuelto cada vez más evidente: las operaciones de contenido están pasando de una mentalidad centrada en el tráfico a una mentalidad centrada en el crecimiento.
A medida que la búsqueda mediante IA y la distribución de contenido se vuelven más complejas, simplemente hacer SEO, publicar contenido y realizar un seguimiento de las impresiones o clics ya no es suficiente. Ahora se espera que los equipos de contenido comprendan el user journey (recorrido del usuario) completo: cómo llegan los usuarios, por qué permanecen, por qué no convierten y qué se debe optimizar en cada paso.
En otras palabras, los roles de contenido están evolucionando gradualmente de ser ejecutores de contenido a participantes e incluso diseñadores de sistemas de crecimiento.
Esto me ha quedado muy claro mientras trabajaba en proyectos de crecimiento de contenido (content growth).
Métricas como las impresiones, los clics, el posicionamiento, el estado de indexación y el volumen de artículos siguen siendo importantes. Pero el verdadero impulsor de los resultados no es si un sitio tiene más contenido, sino si el contenido existente logra conectar la intención de búsqueda con una acción de negocio.
Esto es especialmente cierto para B2B SaaS, sitios web independientes, sitios de comercio electrónico y sitios web de manufactura. Muchas páginas no carecen totalmente de tráfico; lo que ocurre es que el tráfico llega y luego no logra avanzar en el embudo. Los usuarios entran a través de la búsqueda, pero la página no satisface adecuadamente su intención. Los usuarios leen el artículo, pero no ven un CTA (llamada a la acción). Los usuarios hacen clic en un CTA, pero no alcanzan un evento clave (key event).
El problema no es la falta de datos. El problema es la ausencia de una cadena de toma de decisiones que conecte:
Intención de búsqueda → Coincidencia de la intención de la página → Comportamiento del usuario → Acción de negocio → Tarea de optimización → Feedback de rendimiento
Para resolver esto, construimos un sistema interno de diagnóstico de crecimiento de contenido y lo hemos validado en múltiples sitios web independientes en los sectores de e-commerce, manufactura, electrónica de consumo y SaaS de IA.
Este sistema no es un reporte de SEO estándar. Tampoco es una herramienta que simplemente pide a la IA que genere sugerencias de optimización genéricas. En su lugar, conecta GSC, GA4, la base de conocimientos de la marca, las referencias de IA y los registros de rastreo (crawlers) de IA en un flujo de trabajo de diagnóstico a nivel de página.
Ayuda a los equipos a responder las siguientes preguntas:
- ¿Qué consultas (queries) e intenciones llevan a los usuarios a una página?
- ¿La página satisface adecuadamente esa intención?
- Una vez que los usuarios llegan a la página, ¿leen, ven los CTA y hacen clic?
- ¿La información del producto en la página es precisa?
- ¿Los productos de IA generan visitas? ¿Pueden los rastreadores de IA acceder a la página?
- ¿Cómo se puede convertir la evidencia en una tarea de optimización accionable?
- ¿Qué métricas se deben rastrear después de actualizar la página?
El flujo de datos general funciona de la siguiente manera:
Primero, se conectan los datos. Luego, los datos de diferentes fuentes se alinean con la misma URL. Se utilizan clústeres de consultas para identificar la intención de búsqueda. Se emplea el análisis del DOM de la página para determinar si el contenido satisface esa intención. Se combinan los datos del embudo de GSC y GA4 para identificar dónde abandonan los usuarios. Se utiliza la base de conocimientos de la marca para verificar los hechos y datos del contenido. Se utilizan señales de IA/GEO para evaluar el tráfico de referencia de IA y la accesibilidad para los rastreadores. Finalmente, toda la evidencia se convierte en tareas de optimización, y el rendimiento se rastrea de forma continua una vez realizadas las actualizaciones.
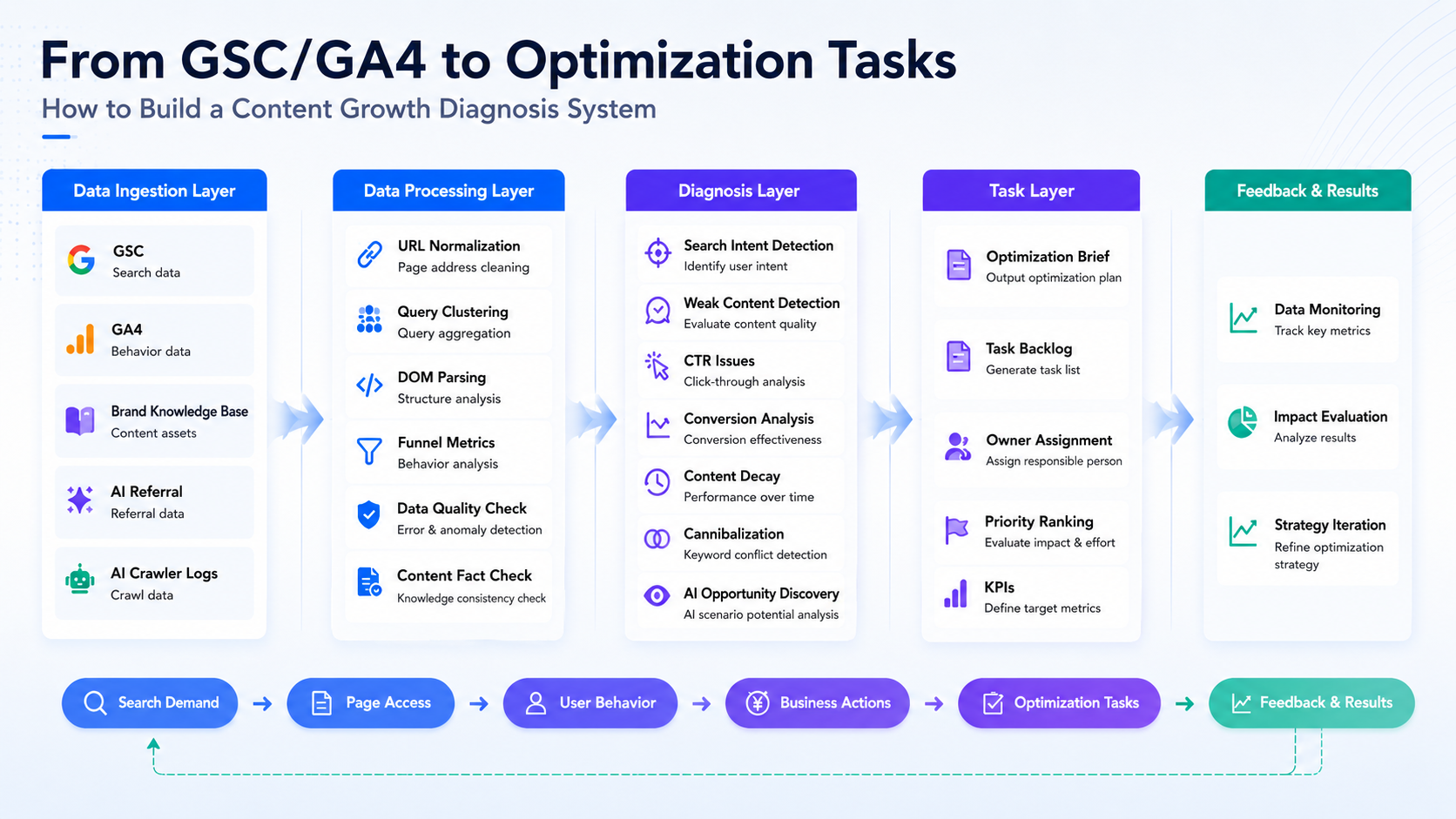
A continuación, se presenta un recorrido por el flujo de trabajo completo.
1. Ingesta de datos: Integrando búsqueda, comportamiento, hechos y señales de IA en una sola cadena
La primera capa es la ingesta de datos. Conectamos principalmente cinco tipos de datos:
- Google Search Console (GSC)
- Google Analytics 4 (GA4)
- Base de conocimientos de la marca
- Sesiones de referencia de IA (AI referral sessions)
- Registros de rastreo de IA (AI crawler logs)
1.1 GSC y GA4
GSC es responsable del rendimiento en el lado de la búsqueda. Proporciona impresiones, clics, CTR, posición media y rendimiento detallado a nivel de consulta.
A través de GSC, el sistema puede identificar qué consultas ayudan a los usuarios a descubrir una página y qué páginas siguen recibiendo impresiones pero están empezando a perder tasa de clics (CTR).
GA4 es responsable del comportamiento en el sitio. Proporciona sesiones de llegada desde búsqueda orgánica, tasa de interacción (engagement rate), comportamiento de scroll, impresiones de CTA, clics en CTA, registros y eventos clave.
A través de GA4, el sistema puede determinar si los usuarios continúan leyendo después de aterrizar en la página, si ven los puntos de entrada del producto, si hacen clic en los CTA y si realizan acciones críticas para el negocio.
GSC y GA4 solo se vuelven poderosos cuando se utilizan juntos.
Si solo observamos GSC, solo vemos lo que sucede en los resultados de búsqueda. Si solo observamos GA4, solo vemos lo que sucede después de que los usuarios entran al sitio. Cuando ambos están conectados, el sistema puede identificar exactamente dónde se estanca un artículo.
Por ejemplo:
-
Altas impresiones pero bajo CTR
Priorizar el título, la meta descripción y la relevancia con respecto a los resultados de búsqueda. -
Muchos clics pero bajo engagement
Priorizar la sección de apertura, la tabla de contenidos, la estructura de la página y la concordancia entre contenido e intención. -
Buen engagement pero pocos clics en CTA
Priorizar los módulos de producto, el copy del CTA y la ubicación del CTA. -
Existen clics en CTA pero los eventos clave siguen siendo bajos
Continúa revisando el flujo de registro, el flujo de demostración (demo path) o el flujo de la landing page.
1.2 Base de conocimiento de marca (Brand Knowledge Base)
La base de conocimiento de marca es responsable de la verificación de hechos sobre el producto.
Los equipos pueden sincronizar las últimas funcionalidades del producto, planes de precios, versiones de capturas de pantalla, mensajes de marca, estándares de comparación con la competencia, respuestas a preguntas frecuentes (FAQ) y actualizaciones importantes del producto en la base de conocimiento.
El sistema luego compara el contenido de la página con la base de conocimiento para determinar si la información del producto en un artículo ha quedado obsoleta.
El propósito de este módulo es proporcionar al LLM una fuente de hechos sobre el producto que sea actual, unificada y confiable.
Sin una base de conocimiento de marca, el sistema solo puede inferir si el contenido podría estar desactualizado basándose en la fecha de publicación, redacción relacionada con el año, capturas de pantalla o la frescura en las SERP. Una vez conectada la base de conocimiento, el sistema puede generar tareas mucho más específicas, tales como:
- Reemplazar capturas de pantalla obsoletas del producto
- Corregir descripciones de planes de precios
- Reescribir tablas de comparación con la competencia
- Sincronizar las respuestas más recientes de FAQ
1.3 Referencias de IA y logs de rastreadores de IA
Los datos de IA/GEO se dividen en dos categorías:
- Sesiones de referencia de IA (AI referral sessions)
- Logs de rastreadores de IA (AI crawler logs)
Las sesiones de referencia de IA provienen de GA4. Muestran si productos como ChatGPT o Perplexity generan visitas reales al sitio web y si dichas visitas generan interacción (engagement) o eventos clave.
Los logs de rastreadores de IA provienen de registros del servidor, Cloudflare, registros de CDN o registros de borde (edge logs). Muestran si rastreadores como GPTBot, PerplexityBot y ClaudeBot han accedido a una página, si el código de estado es normal y si el acceso se ve afectado por reglas de robots, WAF, configuración de CDN o falta de registros.
Esta distinción es importante:
Los rastreadores de IA no son fuentes de tráfico de GA4.
GA4 es adecuado para medir las sesiones de referencia de productos de IA. El acceso de los rastreadores debe verificarse a través de los logs.
Una página puede haber sido rastreada por GPTBot pero no tener sesiones de referencia de ChatGPT. Otra página podría tener tráfico de referencia de Perplexity, pero logs de rastreo incompletos. Solo cuando ambos tipos de señales se revisan en conjunto, el equipo puede determinar si una página necesita contenido más citado (quotable content) o si primero se debe verificar la accesibilidad técnica.
2. Procesamiento de datos: primero alinear las URL y luego construir evidencia a nivel de página
Una vez conectados los datos, el sistema no genera sugerencias de inmediato. Primero procesa la información.
El objetivo de la capa de procesamiento es convertir datos dispersos en evidencia a nivel de página.
2.1 Alineación de datos a nivel de URL
El primer paso es la alineación de URL.
GSC, GA4 y los logs del servidor a menudo registran las direcciones de página de diferentes maneras.
Por ejemplo, el mismo artículo puede aparecer en GSC como una URL completa, en GA4 con parámetros de seguimiento y en los logs del servidor solo como una ruta de página (page path). Si el sistema no estandariza estas direcciones primero, el mismo artículo se dividirá en múltiples registros: clics de búsqueda en un lugar, sesiones en el sitio en otro, clics de CTA en un tercero y acceso de rastreadores en otro lugar distinto.
Por lo tanto, el sistema primero limpia las direcciones de página eliminando parámetros UTM, parámetros de clics de anuncios, anclas de página y otros elementos que no cambian el contenido de la página en sí. Luego, asigna el mismo artículo a una URL canónica única.
Solo después de este paso, las impresiones, clics, sesiones, CTA, eventos clave y registros de rastreadores de IA pueden atribuirse correctamente al mismo artículo.
2.2 Agrupación de consultas (Query Clustering)
Un clúster de consultas consiste en agrupar consultas de búsqueda similares basadas en la intención del usuario.
GSC suele contener una gran cantidad de consultas fragmentadas. Si el equipo de contenido analiza estas consultas una por una, es difícil comprender qué intentan lograr realmente los usuarios.
El sistema agrupa las consultas por intención de búsqueda y las etiqueta con tipos de intención, tales como:
- Intención informativa (definición)
- Intención de selección de herramientas
- Intención de comparación
- Intención comercial
- Intención de precios
- Intención de soporte
- Intención de navegación
En el futuro, esto también podrá mapearse a la intención del usuario en escenarios de marketing de IA y búsqueda por IA.
Esto cambia la perspectiva del equipo, pasando de miles de palabras clave dispersas a un número menor de necesidades del usuario.
También es importante clarificar el límite de esta funcionalidad:
Esta no es una atribución precisa de consulta a conversión.
El sistema no pretende saber que una consulta específica causó directamente un registro (sign-up). En su lugar, resuelve el problema de la coincidencia entre intención de búsqueda y contenido: qué necesidades del usuario atraen a las personas a la página y si la página tiene el contenido correspondiente para satisfacer dichas necesidades.
2.3 Análisis DOM de la página (Page DOM Parsing)
El tercer paso es el análisis del DOM de la página.
El sistema rastrea y analiza la estructura de la página, incluyendo:
- Título
- H1
- H2
- H3
- Secciones de FAQ
- Tablas
- CTA
- Enlaces internos
- Fragmentos del contenido principal (Body content)
Luego determina si cada clúster de consultas tiene una posición de contenido correspondiente en la página.
Por ejemplo, si los usuarios realizan consultas de comparación de herramientas, pero la página solo explica conceptos, sin criterios de selección de herramientas, tablas comparativas o casos de uso, el sistema puede identificar una falta de coincidencia en la intención de búsqueda (weak intent matching).
2.4 Evaluación de la Calidad de los Datos
No todos los datos son adecuados para la generación automática de tareas.
El sistema también verifica si:
- Faltan datos de GSC
- Faltan datos de GA4
- Las URLs están correctamente vinculadas
- El tamaño de la muestra es suficiente
- El seguimiento de eventos está completo
- La base de conocimiento de la marca está disponible
- Los registros (logs) del rastreador de IA están conectados
La calidad de los datos determina directamente lo que el sistema tiene permitido hacer:
| Calidad de Datos | Comportamiento del sistema |
|---|---|
| Alta | Generar borradores de tareas |
| Media | Generar tareas solo tras confirmación manual |
| Baja | Mostrar solo diagnósticos, sin generación automática de tareas |
| Inválida | No evaluar ni generar tareas |
Este paso es crítico.
Un sistema de diagnóstico de contenido no solo debe saber cómo generar recomendaciones; también debe saber cuándo la evidencia es insuficiente y no se debe utilizar la automatización.
3. Bucle de Diagnóstico: De la Intención de Búsqueda a la Coincidencia de Página, Comportamiento del Usuario y Acción Comercial
Una vez completado el procesamiento de datos, el sistema entra en la capa de diagnóstico.
3.1 Lado de la Búsqueda: ¿Qué consultas e intenciones atraen a los usuarios?
El sistema primero revisa las consultas de GSC y los clústeres de consultas (query clusters).
Para una misma página relacionada con la visibilidad en IA (AI visibility), la intención del usuario puede variar significativamente:
- “¿Qué es la visibilidad en IA?” indica una necesidad de comprensión conceptual.
- “Mejores herramientas de visibilidad en IA para SaaS” indica selección de herramientas.
- “Comparar plataformas de monitorización GEO” indica una comparación de soluciones.
- “Rastrear menciones de marca en ChatGPT” indica un flujo de trabajo específico.
Si una página servía anteriormente principalmente para consultas basadas en definiciones, pero las nuevas impresiones provienen ahora de consultas de selección de herramientas, comparación o flujos de trabajo, el sistema identifica que la demanda del usuario ha cambiado.
Este paso responde a una pregunta:
¿Qué tarea intenta completar el usuario al entrar en la página?
3.2 Lado de la Página: ¿La página coincide con la intención de búsqueda del usuario?
Después de identificar los clústeres de consultas, el sistema analiza el DOM de la página.
Las diferentes intenciones requieren estructuras de contenido distintas:
| Tipo de Intención | Contenido necesario |
|---|---|
| Intención de definición | Definición clara, explicación y FAQ |
| Intención de selección de herramientas | Lista de herramientas, criterios de selección, casos de uso y CTA |
| Intención de comparación | Tablas, precios, diferencias y casos de uso |
| Intención de flujo de trabajo | Pasos, métricas, plantillas y errores comunes |
| Intención comercial | Módulos de producto, casos de éxito, CTA y ruta hacia el siguiente paso |
El sistema verifica si estos elementos aparecen en el Título, H1, H2, FAQ, tablas, CTA, o si están ausentes por completo.
Si un clúster de consultas tiene impresiones de búsqueda pero la página aborda esa necesidad de forma superficial, el sistema lo marca como una brecha de contenido (content gap), una nueva oportunidad de consulta o una coincidencia débil con la intención de búsqueda.
Este paso responde a:
¿La página recibió y satisfizo adecuadamente la necesidad del usuario?
3.3 Lado del Comportamiento: ¿Los usuarios leen, ven los CTA y hacen clic?
La coincidencia de contenido no es suficiente. Se necesitan datos de comportamiento de GA4 para verificar si los usuarios efectivamente continúan realizando acciones.
El sistema construye un embudo de página desde la exposición en búsquedas hasta la acción comercial.
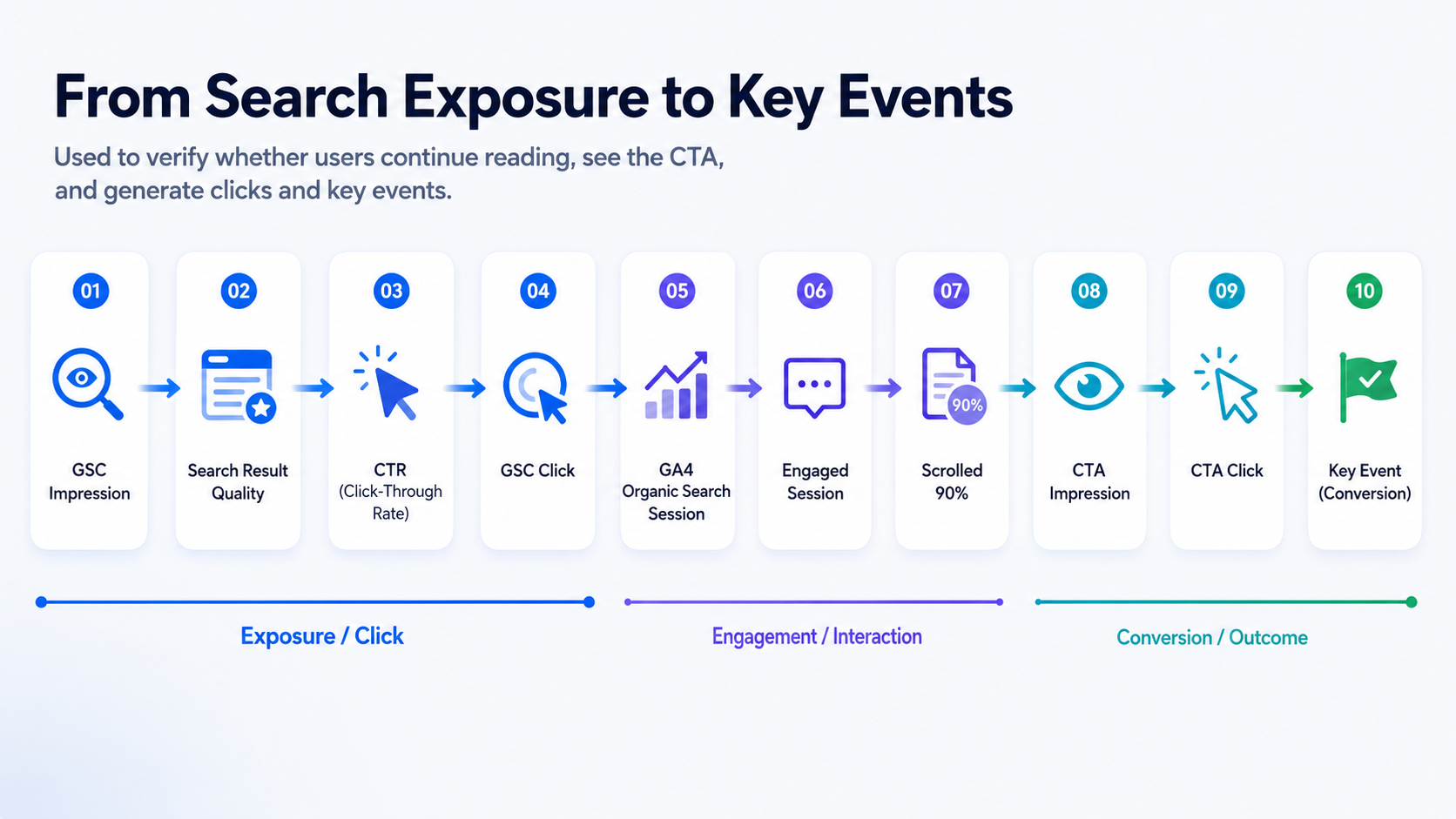
Esta es una de las perspectivas más importantes en el proceso de diagnóstico, ya que ayuda a localizar dónde están atascados los usuarios.
Por ejemplo:
- Si los usuarios llegan a la página pero la interacción (engagement) es baja, el problema puede ser la sección de introducción, la tabla de contenidos, la estructura del contenido o la experiencia de carga de la página.
- Si los usuarios leen la página pero las impresiones de los CTA son bajas, puede que el CTA esté ubicado demasiado abajo.
- Si las impresiones de los CTA son normales pero los clics son bajos, el texto del CTA, el módulo de producto o la intención del usuario pueden no coincidir.
- Si hay clics en los CTA pero los registros, clics en demos o eventos clave son bajos, el problema puede estar en el registro posterior, la demo o la ruta de la página de destino (landing page).
Este paso responde a:
¿Están los usuarios atascados en la lectura, la exposición al CTA, el clic en el CTA o la conversión comercial?
3.4 Lado de los Hechos: ¿El contenido está desactualizado y la información del producto es precisa?
Para contenido B2B SaaS, el contenido desactualizado no es solo una cuestión de fecha de publicación.
Un artículo publicado el año pasado aún puede ser preciso. Otro artículo actualizado el mes pasado podría contener ya precios, funciones, capturas de pantalla o comparaciones con la competencia incorrectos.
La base de conocimiento de la marca alinea el contenido de la página con los hechos más recientes del producto. El sistema verifica si:
- Las funcionalidades mencionadas en la página aún existen
- Los precios siguen vigentes
- Las capturas de pantalla están obsoletas
- Las comparaciones con la competencia siguen el estándar actual
- Las respuestas de las FAQ son coherentes con las respuestas oficiales
Este módulo evita dos problemas comunes:
- Que los artículos antiguos sigan proporcionando a los usuarios información incorrecta del producto.
- Que el LLM genere recomendaciones engañosas basadas en contenido de página desactualizado.
Este paso responde a:
¿Se basan las recomendaciones del sistema en los hechos más recientes sobre el producto?
3.5 Lado de IA/GEO: ¿Puede la IA acceder y citar la página?
El módulo de IA/GEO realiza principalmente dos tipos de evaluaciones:
Primero, las sesiones de referencia de IA muestran si los productos de IA generan visitas reales. Por ejemplo, el sistema verifica si fuentes como ChatGPT, Perplexity y similares generan sesiones, y si dichas sesiones derivan en engagement o eventos clave.
Segundo, los logs de rastreo (crawling) de IA muestran si los rastreadores de IA pueden acceder a la página. El sistema comprueba si GPTBot, PerplexityBot, ClaudeBot y rastreadores similares han visitado la página, si devolvieron códigos de estado 200, 304, 403 o 404, si existe algún motivo de bloqueo y si falta algún registro en los logs.
Estos dos indicadores determinan conjuntamente la siguiente acción:
- Si la página recibe referencias de IA pero tiene una tasa de conversión baja, priorice la concordancia de contenido y la optimización de CTA (llamadas a la acción).
- Si el estado del rastreo es anómalo, priorice las revisiones de las reglas robots, WAF, CDN o la integración de logs.
- Si el acceso del rastreador es normal pero la página carece de definiciones claras, pasos, secciones de preguntas frecuentes (FAQ) y resúmenes estilo respuesta, priorice la creación de contenido citable.
- Si las referencias de IA están creciendo pero los eventos clave son débiles, existe tráfico de IA, pero la correspondencia entre la página y los objetivos de negocio aún requiere mejoras.
Este paso responde a:
En escenarios de búsqueda por IA y citación por LLM, ¿el problema es el tráfico, el contenido o la visibilidad técnica?
4. Identificación del tipo de incidencia: Convertir los resultados del diagnóstico en una cola de operaciones
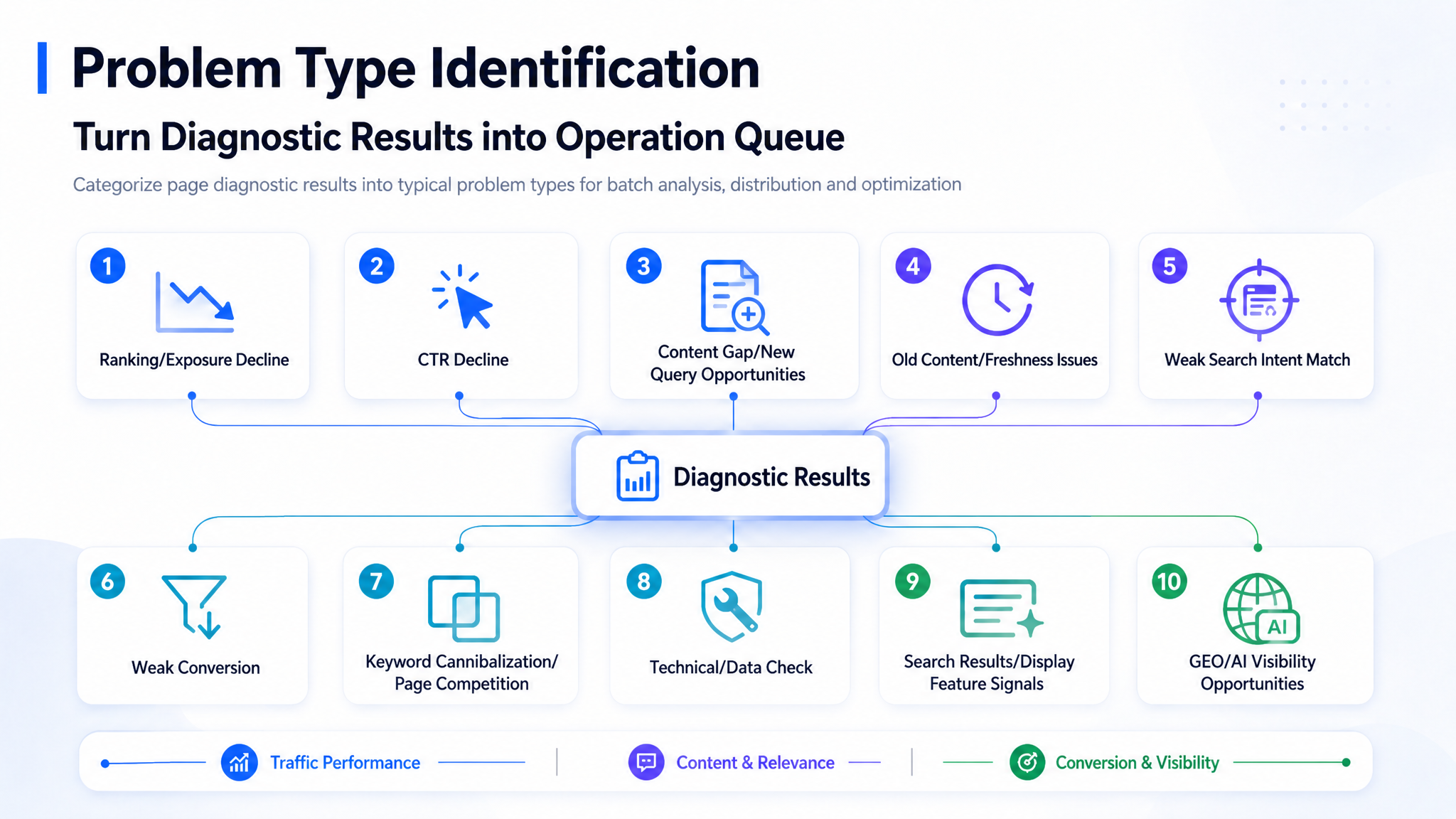
Tras completar los pasos de diagnóstico anteriores, el sistema asigna a cada página un tipo de incidencia específico.
El valor de agrupar las incidencias radica en que la optimización de contenidos se convierte en operaciones por lotes en lugar de ediciones de artículos aislados.
Los grupos de incidencias comunes incluyen:
- Caída de tráfico
- Caída de CTR
- Contenido débil o baja concordancia con la intención de búsqueda
- Contenido antiguo o desactualizado
- Conversión débil
- Páginas duplicadas o canibalizadas
- Oportunidades de contenido perdidas
- Problemas técnicos o de datos
- Problemas de visibilidad en GEO o IA
El grupo de páginas no solo muestra el nombre de la incidencia, sino también:
- Evidencia del detonante
- Instantánea del embudo de la página
- Clústeres de consultas principales afectadas
- Posicionamiento del contenido
- Calidad de los datos
- Resumen de acciones recomendadas
- Responsable
- Estado
Esto permite a los propietarios del contenido gestionar el trabajo por grupos de incidencia cada semana.
Por ejemplo:
- Esta semana: gestionar la caída de CTR.
- La próxima semana: gestionar la conversión débil.
- La semana siguiente: gestionar el contenido desactualizado y la canibalización de páginas.
El equipo ya no edita aleatoriamente la página que parece tener un problema, sino que puede avanzar en la optimización basándose en el tipo de incidencia y su prioridad.
5. Generación de tareas: El sistema arroja recomendaciones de optimización
Los grupos de páginas se utilizan para filtrar, mientras que el diagnóstico a nivel de página individual se utiliza para la generación de tareas.
Al ingresar a la vista de diagnóstico de una página, el sistema reúne toda la evidencia del artículo en una sola vista:
- Embudo de la página
- Clústeres de consultas
- Posiciones de concordancia de contenido
- Comportamiento en página según GA4
- Resultados de verificación de la base de conocimientos de marca
- Calidad de los datos
- Acciones recomendadas
Las acciones recomendadas se determinan principalmente por una combinación de tipos de evidencia:
text
Reglas de tipo de incidencia
+ Clústeres de consultas
+ Posiciones de concordancia de contenido de la página
+ Rendimiento de la página en GA4
+ Verificación de la base de conocimientos de marca
+ Señales de IA/GEO
+ Calidad de los datos
El resultado no es una sugerencia vaga como "optimiza este artículo", sino una tarea que explica claramente:
- Por qué debe actualizarse la página
- Qué parte de la página tiene un problema
- Qué cambios deben realizarse
- Quién debe ser el responsable de la tarea
- Qué métricas deben supervisarse tras la actualización
6. Ejemplo: Cómo funciona la cadena de diagnóstico completa en una página
Tomemos esta página como ejemplo:
https://dageno.ai/en/blog/top-tools-to-track-ai-mentions-in-llms
Paso 1: GSC encuentra demanda de búsqueda
GSC muestra que esta página está empezando a recibir impresiones de consultas relacionadas con "herramientas de seguimiento de menciones de IA".
Si solo observamos GSC, vemos que existe demanda de búsqueda, pero aún no podemos determinar si la página satisface dicha demanda.
Paso 2: El clúster de consultas identifica una intención de selección de herramientas
El sistema agrupa estas consultas en un clúster de intención de selección de herramientas.
Esto significa que los usuarios no solo intentan comprender un concepto, sino que están buscando una categoría de herramientas, comparando capacidades y posiblemente listos para iniciar una prueba o un proceso de compra.
Paso 3: El análisis del DOM encuentra una baja concordancia de intención
El sistema analiza el DOM de la página y encuentra que la sección inicial y la estructura H2 se centran principalmente en explicar el concepto.
La página no ofrece criterios claros de selección de herramientas, dimensiones de comparación ni casos de uso.
En otras palabras, la intención de búsqueda ha virado hacia la selección de herramientas, pero la página sigue comportándose como un artículo de explicación conceptual.
Paso 4: GA4 añade evidencia sobre el comportamiento
GA4 muestra que la página tiene un engagement relativamente alto, pero con pocos clics en el CTA.
Esto significa que los usuarios están dispuestos a leer, pero la página no los guía de manera fluida hacia una acción relacionada con el producto.
Paso 5: La base de conocimientos de marca verifica los hechos del producto
La base de conocimientos de marca detecta que las capturas de pantalla del producto en la página están desactualizadas y que algunas descripciones de funcionalidades no se han actualizado a la última versión.
Si esto no se corrige, el LLM podría seguir utilizando información obsoleta del producto al generar recomendaciones de optimización.
Paso 6: Los registros de rastreo (crawler logs) de IA verifican la accesibilidad técnica
Los registros de rastreo de IA muestran que el GPTBot puede rastrear la página normalmente.
Esto significa que el problema prioritario no es el rastreo técnico. Los problemas más urgentes son si el contenido es lo suficientemente citable, si la información del producto es precisa y si el CTA se ajusta a los usuarios que buscan herramientas.
Borrador de la tarea final
El sistema genera un borrador de tarea como este:
markdown
Página: /blog/top-tools-to-track-ai-mentions-in-llms
Tipo de problema:
- Débil coincidencia con la intención de búsqueda (search intent)
- Conversión deficiente
- Contenido desactualizado
Evidencia desencadenante:
- Las consultas sobre selección de herramientas tienen impresiones de búsqueda
- La sección de introducción y la estructura de los H2 aún se centran en la explicación de conceptos
- El engagement es alto, pero los clics en el CTA son bajos
- La base de conocimientos de marca detecta capturas de pantalla de producto desactualizadas
- El rastreo de GPTBot es normal
Acciones recomendadas:
- Añadir un módulo de criterios de selección de herramientas
- Añadir una tabla comparativa de herramientas
- Actualizar las capturas de pantalla del producto
- Cambiar el CTA genérico de registro por "Ver solución de monitoreo de menciones de IA"
- Añadir contenido de preguntas frecuentes (FAQ)
- Añadir contenido paso a paso que sea más fácil de citar para los LLMs
Métricas a seguir tras la actualización:
- CTR
- Sesiones de búsqueda orgánica
- Clics en el CTA
- Clics en demos
- Eventos clave
- Referencias de IA
- Estado del rastreo (crawler status)De esta manera, un artículo pasa de tener un "rendimiento de datos poco claro" a una tarea concreta.
El equipo sabe ahora:
- Por qué el artículo necesita ser modificado
- Dónde está el problema
- Qué necesita actualizarse
- Quién debe encargarse
- Qué métricas deben revisarse después
7. Monitoreo y revisión del rendimiento
Un verdadero bucle de crecimiento de contenido (content growth loop) también necesita retroalimentar el sistema con los datos de rendimiento después de que un artículo sea actualizado.
La versión actual ya puede ejecutar el flujo de trabajo principal, desde la ingesta de datos hasta el diagnóstico de la página y la generación del borrador de la tarea.
La siguiente etapa es añadir un seguimiento del rendimiento post-ejecución, conectando cada actualización de contenido con los cambios subsiguientes en las métricas.
El sistema registrará:
- Tiempo de generación de la tarea
- Módulos actualizados
- Fecha de lanzamiento
- Responsable (Owner)
- Estado de la tarea
- Datos de rendimiento de seguimiento
Esto permite a los equipos evaluar si cada acción de optimización produce resultados reales.
8. Qué falta por construir
En este punto, el sistema ya puede ejecutar la cadena de diagnóstico principal. Sin embargo, todavía es necesario mejorar varias capacidades.
8.1 Agrupación de intención de búsqueda (Query Intent Clustering)
La versión actual se basa principalmente en la similitud de texto y juicios basados en reglas. En industrias verticales, esto ya cubre la mayoría de las consultas comunes.
Sin embargo, las consultas de cola larga (long-tail), los términos emergentes y las consultas que son semánticamente similares pero diferentes en cuanto a intención, podrían seguir agrupándose incorrectamente.
En el futuro, el sistema combinará la coincidencia de palabras clave y el juicio basado en LLM para clasificar los clústeres de consultas con mayor precisión.
Para los clústeres de intención de baja confianza, el sistema los marcará automáticamente como "requiere confirmación manual", evitando que se generen tareas incorrectas cuando la evidencia sea insuficiente.
8.2 Actualización automática de la base de conocimientos de marca
La base de conocimientos de marca actual todavía se mantiene principalmente mediante importación manual. Esto funciona bien para centralizar inicialmente información básica como las funcionalidades del producto, precios, capturas de pantalla, respuestas a FAQ y estándares de mensajes de la competencia.
Pero a largo plazo, la base de conocimientos no puede depender solo del mantenimiento manual.
El siguiente paso es conectar los registros de cambios (changelogs) del producto, datos del CMS o fuentes de documentación interna, para que la versión de la base de conocimientos se actualice automáticamente a medida que el producto evoluciona.
Esto hará que las revisiones de contenido desactualizado dependan menos de la revisión manual. El sistema también podrá identificar con mayor rapidez funcionalidades obsoletas, capturas de pantalla antiguas, precios incorrectos y descripciones de producto que ya no coinciden con los mensajes actuales.
8.3 Seguimiento del rendimiento
El sistema ya puede determinar qué artículo debe actualizarse, por qué, dónde debe cambiarse y cómo generar una tarea de optimización respaldada por evidencia.
El siguiente paso es añadir un seguimiento del rendimiento posterior a la ejecución de la tarea y conectar cada actualización de contenido con los cambios en las métricas posteriores.
Una vez completado esto, los equipos de contenido podrán comprender:
- Si una optimización realmente generó crecimiento
- Qué tipos de actualizaciones son más efectivas
- Qué páginas aún necesitan una iteración adicional
Conclusión
El objetivo de este sistema de diagnóstico de crecimiento de contenido no es proporcionar otro informe de SEO innecesario.
Su objetivo es convertir la optimización del tráfico orgánico en un proceso que sea:
- Ejecutable
- Rastreable
- Revisable
- Conectado a los resultados de negocio
Conecta los datos de búsqueda, el contenido de la página, el comportamiento del usuario, los hechos de la marca, la visibilidad en IA/GEO (Generative Engine Optimization), las tareas de optimización y la retroalimentación del rendimiento en un ciclo cerrado.
Como resultado, el equipo de contenido ya no recibe instrucciones vagas como "optimizar el artículo".
En su lugar, pueden comprender claramente:
- Por qué es necesario cambiar la página
- Dónde está el problema
- Qué debe actualizarse
- Quién debe ejecutar la tarea
- Qué métricas deben verificarse después de la actualización
GitHub: github.com/dageno-ai/organic-content-intelligence
Si también está creando un sitio web independiente para mercados extranjeros, enfocándose en el crecimiento de contenido o en la búsqueda mediante IA, y desea discutir esta solución o conocer más sobre los detalles de implementación del sistema, puede añadir WeChat: dudulhc.
About the Author

Actualizado por
Dageno
Related Articles
Dentro de Dageno AI: El sistema de embudo completo GEO explicado por Peter Rota

Peter Rota • May 26, 2026
Las compras con IA están reescribiendo el descubrimiento de productos: las marcas de comercio electrónico transfronterizo deben entender primero las nuevas reglas

Tim • Jun 18, 2026
Introducción al Centro de Diagnóstico Dageno AI (1) - Traduciendo señales complejas de IA en crecimiento
Tim • May 22, 2026
Dageno Agencia Socio Manual: Escala Tu Agencia con Crecimiento Impulsado por IA
Tim • May 22, 2026