Do GSC/GA4 às Tarefas de Otimização: Como Construir um Sistema de Diagnóstico de Crescimento de Conteúdo
Uma estrutura prática para transformar dados do GSC, GA4, conhecimento de marca, referências de IA e rastreadores em tarefas acionáveis de otimização de conteúdo.
Rastreie a visibilidade da pesquisa de IASem instalação
Atualizado por
10 minutos de leitura
Atualizado em Jun 26, 2026
Nos últimos anos, uma mudança tornou-se cada vez mais evidente: as operações de conteúdo estão saindo de uma mentalidade focada em tráfego para uma mentalidade de crescimento (growth mindset).
À medida que a busca por IA (AI Search) e a distribuição de conteúdo se tornam mais complexas, simplesmente fazer SEO, publicar conteúdo e monitorar impressões ou cliques já não é mais suficiente. Agora, espera-se que as equipes de conteúdo compreendam a jornada completa do usuário: como os usuários chegam, por que permanecem, por que não convertem e o que deve ser otimizado em cada etapa.
Em outras palavras, os papéis de conteúdo estão evoluindo gradualmente de executores de conteúdo para participantes e até mesmo designers de sistemas de crescimento.
Isso tornou-se muito claro para mim enquanto trabalhava em projetos de content growth.
Métricas como impressões, cliques, rankings, status de indexação e volume de artigos ainda importam. Mas o verdadeiro impulsionador de resultados não é se um site possui mais conteúdo, e sim se o conteúdo existente conecta com sucesso a demanda de busca a uma ação de negócio.
Isso é especialmente verdadeiro para B2B SaaS, sites independentes, e-commerce e sites de manufatura. Muitas páginas não estão completamente sem tráfego. Em vez disso, o tráfego chega e não consegue avançar no funil. Os usuários entram via busca, mas a página não atende adequadamente à sua intenção. Os usuários leem o artigo, mas não veem uma CTA (chamada para ação). Os usuários clicam em uma CTA, mas não completam um evento-chave.
O problema não é a falta de dados. O problema é a ausência de uma cadeia de tomada de decisão que conecte:
Demanda de busca → Correspondência de intenção da página → Comportamento do usuário → Ação de negócio → Tarefa de otimização → Feedback de performance
Para resolver isso, criamos um sistema interno de diagnóstico de content growth e validamo-lo em vários sites independentes nas áreas de e-commerce, manufatura, eletrônicos de consumo e SaaS de IA.
Este sistema não é um relatório de SEO padrão. Também não é uma ferramenta que simplesmente pede à IA para gerar sugestões de otimização genéricas. Em vez disso, ele conecta GSC, GA4, a base de conhecimento da marca, referências de IA e logs de crawlers de IA em um fluxo de trabalho de diagnóstico em nível de página.
Ele ajuda as equipes a responder às seguintes perguntas:
- Quais consultas (queries) e intenções levam os usuários a uma página?
- A página corresponde e satisfaz adequadamente essa intenção?
- Após os usuários chegarem à página, eles leem, veem as CTAs e clicam nelas?
- As informações do produto na página estão precisas?
- Produtos de IA trazem visitas e os crawlers de IA conseguem acessar a página?
- Como as evidências podem ser transformadas em uma tarefa de otimização acionável?
- Quais métricas devem ser rastreadas após a atualização da página?
O fluxo geral de dados funciona da seguinte forma:
Primeiro, os dados são conectados. Depois, os dados de diferentes fontes são alinhados à mesma URL. Clusters de consulta são usados para identificar a intenção de busca. A análise do DOM da página é utilizada para determinar se o conteúdo satisfaz essa intenção. Os dados de funil do GSC e GA4 são combinados para identificar onde os usuários abandonam a página. A base de conhecimento da marca é usada para verificar a veracidade do conteúdo. Sinais de IA/GEO são usados para avaliar o tráfego de referência de IA e a acessibilidade dos crawlers. Por fim, todas as evidências são convertidas em tarefas de otimização, e o desempenho é continuamente monitorado após as alterações serem publicadas.
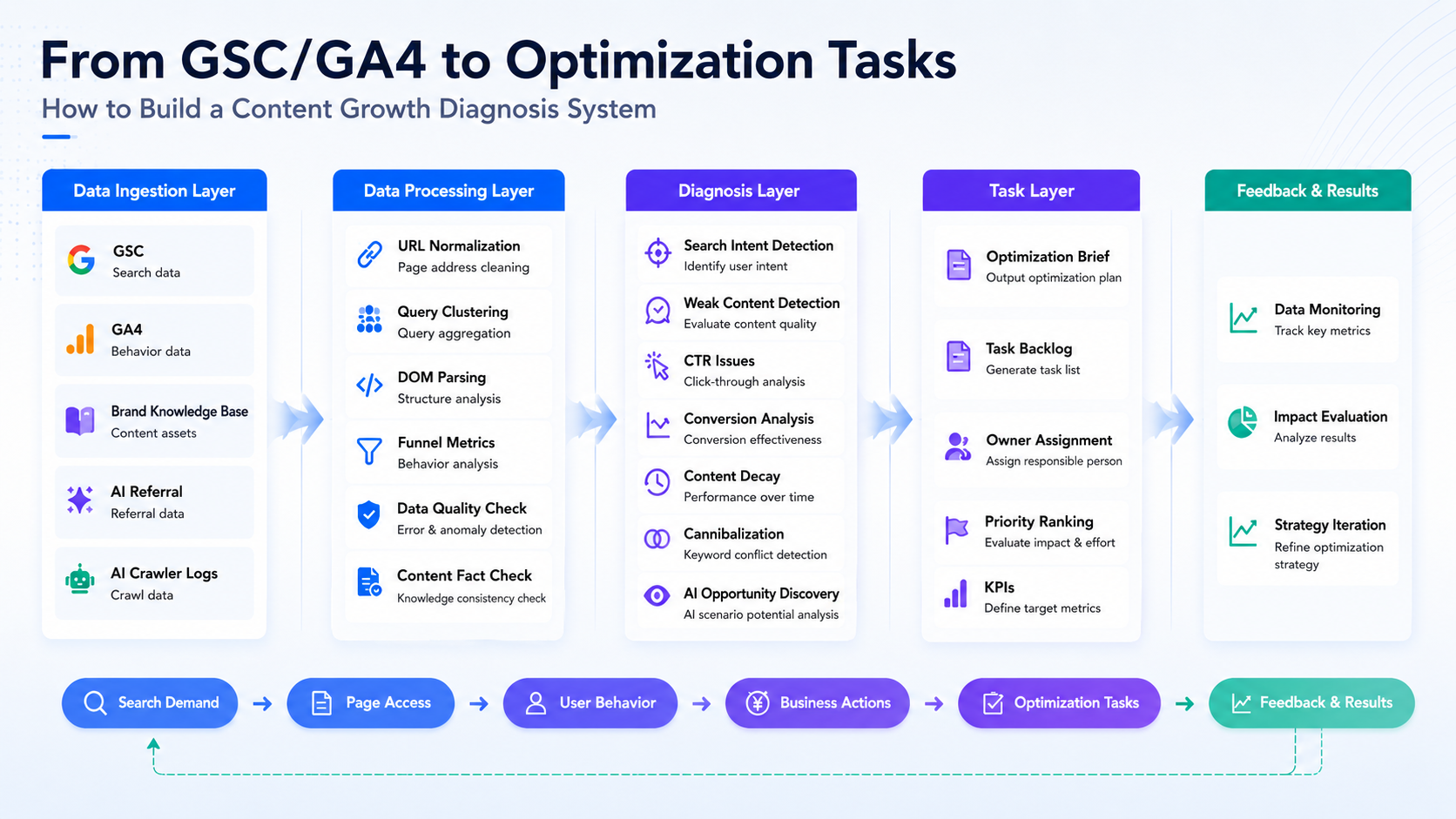
Abaixo está um passo a passo do fluxo de trabalho completo.
1. Ingestão de Dados: Colocando Busca, Comportamento, Fatos e Sinais de IA em uma única cadeia
A primeira camada é a ingestão de dados. Conectamos principalmente cinco tipos de dados:
- Google Search Console (GSC)
- Google Analytics 4 (GA4)
- Base de conhecimento da marca
- Sessões de referência de IA
- Logs de crawlers de IA
1.1 GSC e GA4
O GSC é responsável pelo desempenho na busca. Ele fornece impressões, cliques, CTR, posição média e desempenho detalhado em nível de consulta.
Por meio do GSC, o sistema pode identificar quais consultas ajudam os usuários a descobrir uma página e quais páginas ainda recebem impressões, mas estão começando a perder taxa de cliques (CTR).
O GA4 é responsável pelo comportamento no site. Ele fornece sessões de landing orgânicas, taxa de engajamento, comportamento de scroll (rolagem), impressões de CTA, cliques em CTA, inscrições e eventos-chave.
Por meio do GA4, o sistema pode determinar se os usuários continuam lendo após chegarem à página, se veem pontos de entrada de produtos, se clicam nas CTAs e se realizam ações críticas para o negócio.
O GSC e o GA4 só se tornam poderosos quando usados em conjunto.
Se olharmos apenas para o GSC, veremos apenas o que acontece nos resultados de busca. Se olharmos apenas para o GA4, veremos apenas o que acontece após os usuários entrarem no site. Quando os dois são conectados, o sistema consegue identificar exatamente onde um artigo está travado.
Por exemplo:
-
Altas impressões, mas baixo CTR
Priorize o título, a meta description e a relevância nos resultados de busca. -
Altos cliques, mas baixo engajamento
Priorize a seção inicial, o sumário, a estrutura da página e a correspondência entre conteúdo e intenção. -
Bom engajamento, mas poucos cliques em CTAs
Priorize os módulos de produto, o copy da CTA e o posicionamento da CTA. -
Cliques em CTAs existem, mas as principais conversões permanecem baixas
Continue verificando o fluxo de registro, fluxo de demonstração ou o funil da landing page.
1.2 Base de Conhecimento da Marca (Brand Knowledge Base)
A base de conhecimento da marca é responsável pela verificação de fatos do produto (product fact verification).
As equipes podem sincronizar os recursos mais recentes do produto, planos de preços, versões de capturas de tela (screenshots), mensagens de marca, padrões de comparação com concorrentes, respostas de FAQ e atualizações importantes do produto na base de conhecimento.
O sistema então compara o conteúdo da página com a base de conhecimento para determinar se as informações do produto em um artigo ficaram obsoletas.
O objetivo deste módulo é fornecer ao LLM uma fonte atual, unificada e confiável de fatos sobre o produto.
Sem uma base de conhecimento da marca, o sistema só pode inferir se o conteúdo pode estar desatualizado com base na data de publicação, termos relacionados ao ano, capturas de tela ou frescor (freshness) do SERP. Após a conexão da base de conhecimento, o sistema pode gerar tarefas muito mais específicas, tais como:
- Substituir capturas de tela de produtos desatualizadas
- Corrigir descrições de planos de preços
- Reescrever tabelas de comparação de concorrentes
- Sincronizar as respostas de FAQ mais recentes
1.3 Referências de IA e Logs de Crawlers de IA
Os dados de IA/GEO são divididos em duas categorias:
- Sessões de referência de IA
- Logs de crawlers de IA
As sessões de referência de IA vêm do GA4. Elas mostram se produtos como ChatGPT ou Perplexity trazem visitas reais para o site e se essas visitas geram engajamento ou eventos-chave (key events).
Os logs de crawlers de IA vêm de logs de servidor, Cloudflare, logs de CDN ou edge logs. Eles mostram se crawlers como GPTBot, PerplexityBot e ClaudeBot acessaram uma página, se o código de status está normal e se o acesso é afetado por regras de robots, WAF, configuração de CDN ou logs ausentes.
Esta distinção é importante:
Crawlers de IA não são fontes de tráfego do GA4.
O GA4 é adequado para medir sessões de referência de produtos de IA. O acesso de crawlers deve ser verificado através de logs.
Uma página pode ter sido rastreada (crawled) pelo GPTBot, mas não ter sessões de referência do ChatGPT. Outra página já pode ter tráfego de referência do Perplexity, mas logs de crawler incompletos. Somente quando ambos os sinais são analisados em conjunto é que a equipe pode determinar se uma página precisa de mais conteúdo citável ou se a acessibilidade técnica deve ser verificada primeiro.
2. Processamento de Dados: Alinhe primeiro as URLs, depois construa evidências em nível de página
Após a conexão dos dados, o sistema não gera sugestões imediatamente. Ele processa os dados primeiro.
O objetivo da camada de processamento é transformar dados dispersos em evidências em nível de página.
2.1 Alinhamento de Dados em Nível de URL
O primeiro passo é o alinhamento de URLs.
GSC, GA4 e logs de servidor frequentemente registram endereços de página de maneiras diferentes.
Por exemplo, o mesmo artigo pode aparecer no GSC como uma URL completa, no GA4 com parâmetros de rastreamento e nos logs do servidor apenas como um caminho (path) de página. Se o sistema não padronizar esses endereços primeiro, o mesmo artigo será dividido em múltiplos registros: cliques de busca em um lugar, sessões no site em outro, cliques em CTA em outro e acesso de crawler em uma localização distinta.
Portanto, o sistema primeiro limpa os endereços das páginas removendo parâmetros UTM, parâmetros de cliques em anúncios, âncoras de página e outros elementos que não alteram o conteúdo da página em si. Em seguida, ele mapeia o mesmo artigo para uma única URL canônica.
Somente após esta etapa as impressões, cliques, sessões, CTAs, eventos-chave e registros de crawlers de IA podem ser corretamente atribuídos ao mesmo artigo.
2.2 Agrupamento de Queries (Query Clustering)
Um cluster de queries significa agrupar termos de pesquisa (queries) semelhantes com base na intenção do usuário.
O GSC frequentemente contém um grande número de consultas fragmentadas. Se a equipe de conteúdo analisar essas consultas uma a uma, é difícil entender o que os usuários estão realmente tentando realizar.
O sistema agrupa as consultas por intenção de busca e as rotula com tipos de intenção, tais como:
- Intenção de definição
- Intenção de seleção de ferramentas
- Intenção de comparação
- Intenção comercial
- Intenção de preços
- Intenção de suporte
- Intenção navegacional
No futuro, isso também poderá ser mapeado para a intenção do usuário em cenários de marketing de IA e busca por IA.
Isso muda a visão da equipe de milhares de palavras-chave dispersas para um número menor de necessidades do usuário.
Também é importante esclarecer o limite desta funcionalidade:
Esta não é uma atribuição precisa de consulta para conversão.
O sistema não pretende saber que uma consulta específica causou diretamente uma inscrição (sign-up) específica. Em vez disso, ele resolve o problema da correspondência entre intenção de busca e conteúdo: quais necessidades do usuário levam as pessoas à página e se a página possui conteúdo correspondente para atender a essas necessidades.
2.3 Parsing de DOM da Página
O terceiro passo é o parsing do DOM da página.
O sistema rastreia e analisa a estrutura da página, incluindo:
- Título
- H1
- H2
- H3
- Seções de FAQ
- Tabelas
- CTAs
- Links internos
- Fragmentos de conteúdo do corpo
Em seguida, ele determina se cada cluster de queries possui uma posição de conteúdo correspondente na página.
Por exemplo, se os usuários buscam por consultas de comparação de ferramentas, mas a página apenas explica conceitos, sem critérios de seleção de ferramentas, tabelas comparativas ou casos de uso, o sistema pode identificar uma correspondência de intenção fraca (weak intent matching).
2.4 Avaliação da Qualidade dos Dados
Nem todos os dados são adequados para a geração automática de tarefas.
O sistema também verifica se:
- Dados do GSC estão faltando
- Dados do GA4 estão faltando
- URLs estão mapeadas corretamente
- O tamanho da amostra é suficiente
- O rastreamento de eventos (event tracking) está completo
- A base de conhecimento da marca está disponível
- Os logs do crawler de IA estão conectados
A qualidade dos dados determina diretamente o que o sistema tem permissão para fazer:
| Qualidade dos Dados | Comportamento do Sistema |
|---|---|
| Alta | Gera rascunhos de tarefas |
| Média | Gera tarefas apenas após confirmação manual |
| Baixa | Exibe apenas diagnósticos, sem geração automática de tarefas |
| Inválido | Não julga nem gera tarefas |
Esta etapa é fundamental.
Um sistema de diagnóstico de conteúdo não deve apenas saber como gerar recomendações. Ele também deve saber quando as evidências são insuficientes e a automação não deve ser utilizada.
3. Ciclo de Diagnóstico: Da Demanda de Busca ao Mapeamento de Página, Comportamento do Usuário e Ação de Negócio
Após a conclusão do processamento de dados, o sistema entra na camada de diagnóstico.
3.1 Lado da Busca: Quais Consultas e Intenções Atraem os Usuários?
O sistema analisa primeiro as consultas (queries) do GSC e os clusters de consulta.
Para a mesma página relacionada à visibilidade de IA, a intenção do usuário pode variar significativamente:
- “O que é visibilidade de IA?” indica compreensão conceitual.
- “Melhores ferramentas de visibilidade de IA para SaaS” indica seleção de ferramentas.
- “Comparar plataformas de monitoramento GEO” indica comparação de soluções.
- “Rastrear menções à marca no ChatGPT” indica um fluxo de trabalho específico.
Se uma página atendia anteriormente principalmente a consultas baseadas em definições, mas novas impressões agora vêm de consultas de seleção de ferramentas, comparação ou fluxos de trabalho, o sistema identifica que a demanda do usuário mudou.
Esta etapa responde a uma pergunta:
Qual tarefa o usuário está tentando concluir ao entrar na página?
3.2 Lado da Página: A Página Corresponde à Intenção de Busca do Usuário?
Após a identificação dos clusters de consulta, o sistema analisa o DOM da página.
Intenções diferentes exigem estruturas de conteúdo diferentes:
| Tipo de Intenção | Conteúdo Necessário |
|---|---|
| Intenção de definição | Definição clara, explicação e FAQ |
| Intenção de seleção de ferramenta | Lista de ferramentas, critérios de seleção, casos de uso e CTA |
| Intenção de comparação | Tabelas, preços, diferenças e casos de uso |
| Intenção de fluxo de trabalho | Passos, métricas, modelos e erros comuns |
| Intenção comercial | Módulos de produto, estudos de caso, CTA e caminho para a próxima etapa |
O sistema verifica se esses elementos aparecem no Título, H1, H2, FAQ, tabelas, CTAs ou se eles estão completamente ausentes.
Se um cluster de consulta tem impressões de busca, mas a página cobre essa necessidade de forma rasa, o sistema marca isso como uma lacuna de conteúdo (content gap), uma nova oportunidade de consulta ou uma correspondência de intenção de busca fraca.
Esta etapa responde:
A página recebeu e satisfez adequadamente a necessidade do usuário?
3.3 Lado do Comportamento: Os Usuários Leem, Veem CTAs e Clicam?
O mapeamento de conteúdo por si só não é suficiente. Dados de comportamento do GA4 são necessários para verificar se os usuários realmente continuam a realizar ações.
O sistema constrói um funil de página desde a exposição na busca até a ação de negócio.
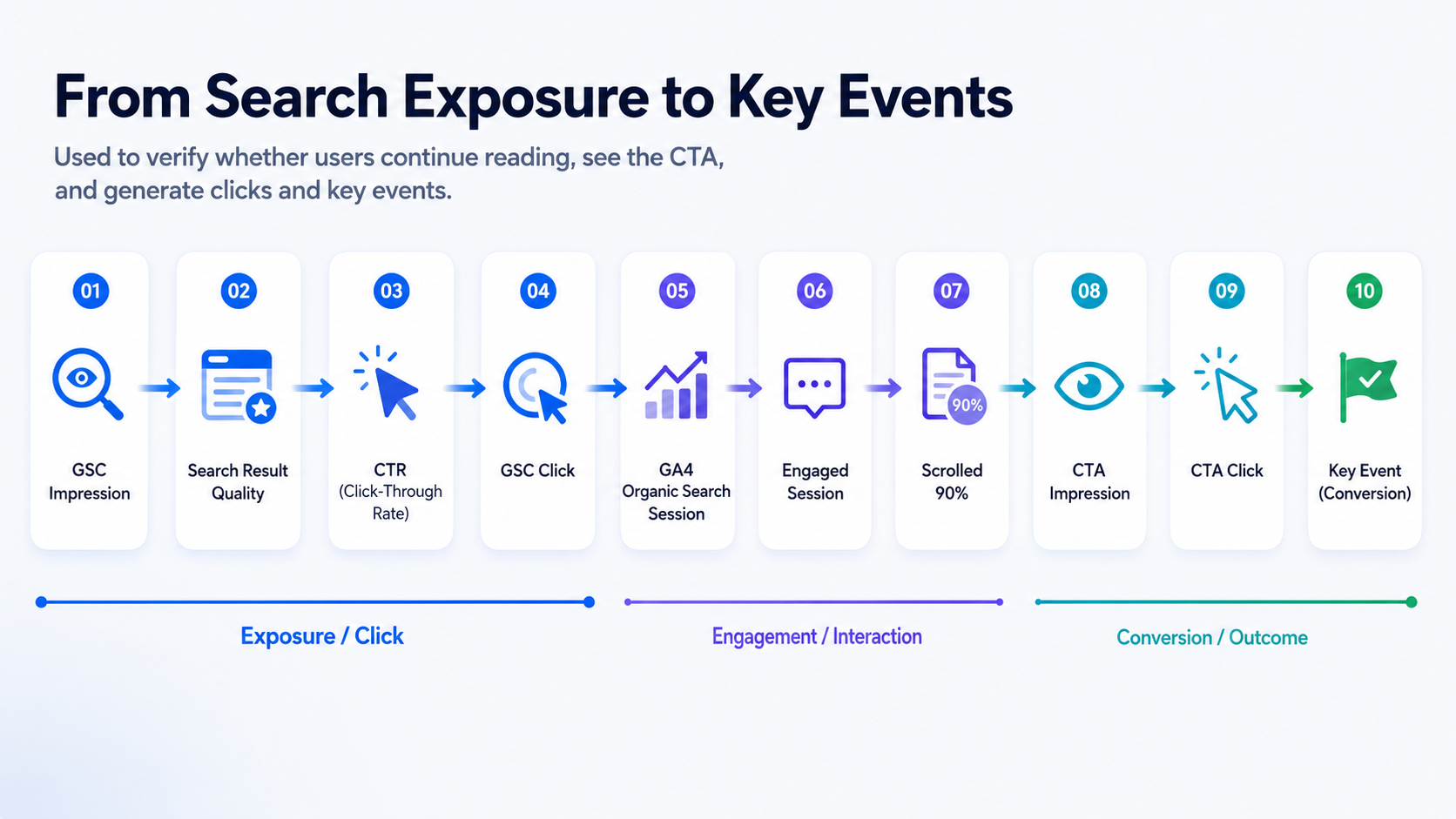
Esta é uma das perspectivas mais importantes no processo de diagnóstico, pois ajuda a localizar onde os usuários estão travados.
Por exemplo:
- Se os usuários acessam a página, mas o engajamento é baixo, o problema pode ser a seção de introdução, o índice, a estrutura do conteúdo ou a experiência de carregamento da página.
- Se os usuários leem a página, mas as impressões de CTA são baixas, o CTA pode estar posicionado muito abaixo.
- Se as impressões de CTA são normais, mas os cliques são baixos, o texto do CTA, o módulo do produto ou a intenção do usuário podem estar desalinhados.
- Se existem cliques no CTA, mas as inscrições, cliques para demo ou eventos-chave são baixos, o problema pode estar no registro subsequente, na demo ou no caminho da landing page.
Esta etapa responde:
Os usuários estão presos na leitura, na exposição do CTA, no clique do CTA ou na conversão de negócio?
3.4 Lado dos Fatos: O Conteúdo está Desatualizado e as Informações do Produto estão Precisas?
Para conteúdo B2B SaaS, conteúdo desatualizado não é apenas uma questão de data de publicação.
Um artigo publicado no ano passado ainda pode estar preciso. Outro artigo atualizado no mês passado já pode conter preços, recursos, capturas de tela ou comparações de concorrentes incorretos.
A base de conhecimento da marca alinha o conteúdo da página com os fatos mais recentes do produto. O sistema verifica se:
- Os recursos mencionados na página ainda existem
- Os preços ainda estão atuais
- As capturas de tela estão desatualizadas
- As comparações de concorrentes seguem o padrão atual
- As respostas do FAQ são consistentes com as respostas oficiais
Este módulo evita dois problemas comuns:
- Artigos antigos continuam fornecendo aos usuários informações incorretas sobre o produto.
- O LLM gera recomendações enganosas baseadas em conteúdo de página desatualizado.
Esta etapa responde:
As recomendações do sistema baseiam-se nos fatos mais recentes sobre o produto?
3.5 Lado da IA/GEO: As fontes de IA conseguem acessar e citar a página?
O módulo de IA/GEO realiza principalmente dois julgamentos.
Primeiro, as sessões de referência de IA mostram se os produtos de IA trazem visitas reais. Por exemplo, o sistema verifica se o ChatGPT, o Perplexity e fontes similares trazem sessões, e se essas sessões geram engajamento ou eventos-chave (key events).
Segundo, os logs de rastreamento (crawler logs) de IA mostram se os crawlers de IA conseguem acessar a página. O sistema verifica se o GPTBot, PerplexityBot, ClaudeBot e crawlers similares visitaram a página, se retornaram códigos 200, 304, 403 ou 404, se existe um motivo de bloqueio e se há logs ausentes.
Esses dois sinais juntos determinam a próxima ação:
- Se a página possui referências de IA, mas com conversão fraca, priorize a correspondência de conteúdo e a otimização de CTAs.
- Se o status do crawler estiver anormal, priorize verificações de regras de robots, WAF, CDN ou integração de logs.
- Se o acesso do crawler estiver normal, mas a página carecer de definições claras, etapas, FAQs e resumos em formato de resposta, priorize conteúdo citável (quotable content).
- Se as referências de IA estiverem crescendo, mas os eventos-chave forem fracos, o tráfego de IA existe, mas a correspondência da página do lado do negócio ainda precisa de melhorias.
Esta etapa responde a:
Em cenários de busca por IA e citações de LLM, o problema é o tráfego, o conteúdo ou a visibilidade técnica?
4. Identificação do Tipo de Problema: Transforme Resultados de Diagnóstico em uma Fila de Operações
Após concluir as etapas de diagnóstico acima, o sistema atribui cada página a um tipo de problema específico.
O valor do agrupamento de problemas é que a otimização de conteúdo passa a ser feita como operações em lote, em vez de edições pontuais de artigos.
Grupos de problemas comuns incluem:
- Queda de tráfego
- Queda de CTR
- Conteúdo fraco ou correspondência fraca de intenção de busca
- Conteúdo antigo ou desatualizado
- Fraqueza na conversão
- Páginas duplicadas ou concorrentes
- Oportunidades de conteúdo ausentes
- Problemas técnicos ou de dados
- Problemas de visibilidade em GEO ou IA
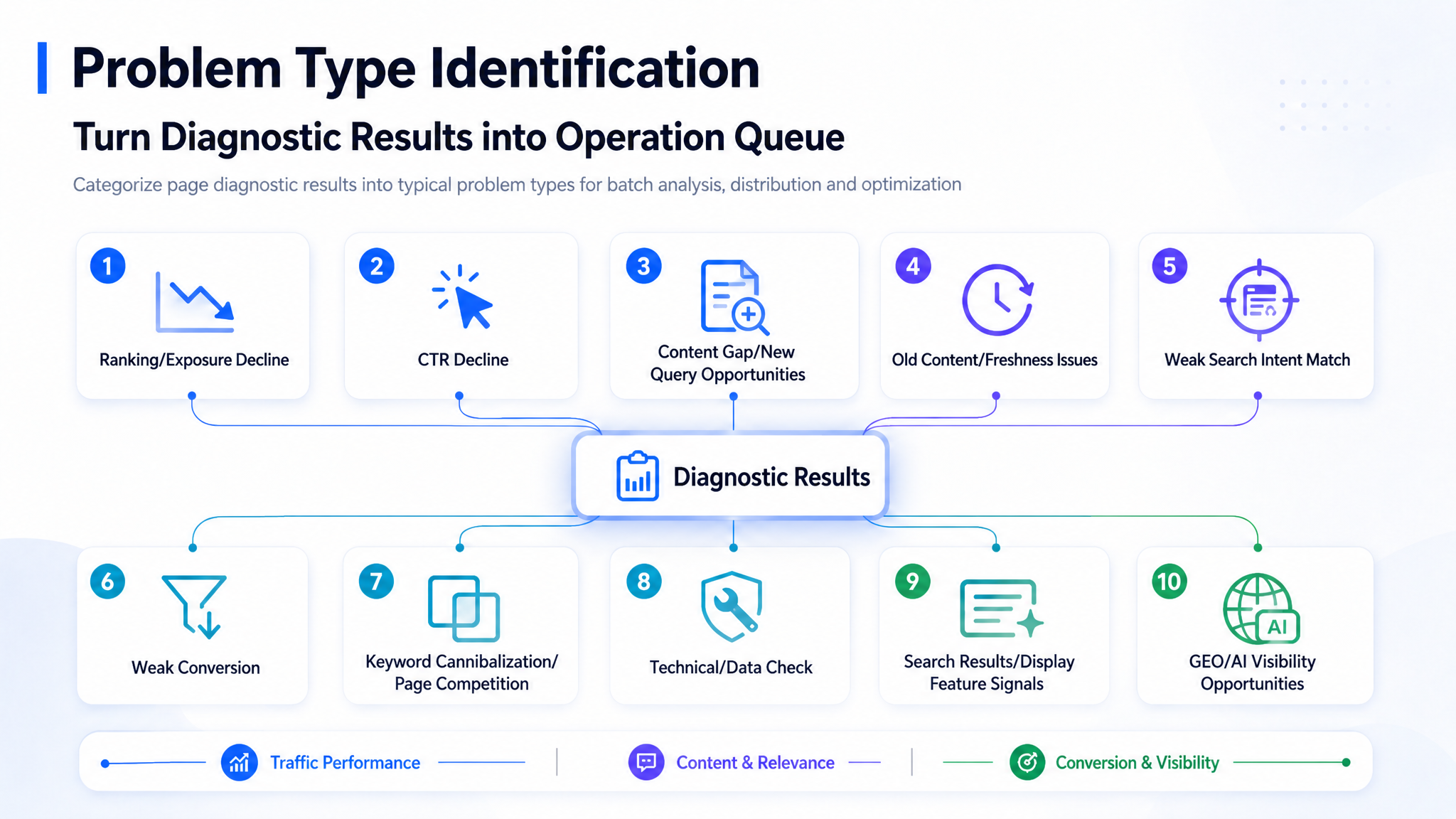
O grupo de páginas não exibe apenas nomes de problemas. Ele também mostra:
- Evidências do gatilho
- Snapshot do funil da página
- Principais clusters de consulta afetados
- Posicionamentos de conteúdo
- Qualidade dos dados
- Resumo de ações recomendadas
- Responsável
- Status
Isso permite que os responsáveis pelo conteúdo gerenciem o trabalho por grupo de problemas a cada semana.
Por exemplo:
- Esta semana: tratar a queda de CTR.
- Próxima semana: tratar a conversão fraca.
- Na semana seguinte: tratar conteúdo desatualizado e canibalização de páginas.
A equipe não edita mais aleatoriamente qualquer página que pareça problemática. Em vez disso, eles podem progredir no trabalho de otimização por tipo de problema e prioridade.
5. Geração de Tarefas: O Sistema Produz Recomendações de Otimização
Grupos de páginas são usados para filtragem. Diagnósticos de página única são usados para geração de tarefas.
Ao entrar em uma visualização de diagnóstico de página única, o sistema coloca todas as evidências de um artigo em uma página:
- Funil da página
- Clusters de consulta
- Posições de correspondência de conteúdo
- Comportamento da página no GA4
- Resultados da verificação da base de conhecimento da marca
- Qualidade dos dados
- Ações recomendadas
As ações recomendadas são determinadas principalmente pela combinação de tipos de evidências:
text
Regras de tipo de problema
+ Clusters de consulta
+ Posições de correspondência de conteúdo da página
+ Performance da página no GA4
+ Verificação da base de conhecimento da marca
+ Sinais de IA/GEO
+ Qualidade dos dados
A saída não é uma sugestão vaga como “otimize este artigo”. Ela deve se tornar uma tarefa que explica claramente:
- Por que esta página precisa ser atualizada
- Qual parte da página apresenta um problema
- O que deve ser alterado
- Quem deve ser o responsável pela tarefa
- Quais métricas devem ser verificadas após a atualização
6. Exemplo: Como a cadeia de diagnóstico completa funciona em uma página
Pegue esta página como exemplo:
https://dageno.ai/en/blog/top-tools-to-track-ai-mentions-in-llms
Etapa 1: O GSC encontra demanda de busca
O GSC (Google Search Console) mostra que esta página está começando a receber impressões de consultas relacionadas a “ferramentas de rastreamento de menções de IA”.
Se olharmos apenas para o GSC, podemos ver que há demanda de busca, mas ainda não conseguimos determinar se a página satisfaz essa demanda.
Etapa 2: O agrupamento de consultas identifica a intenção de seleção de ferramentas
O sistema agrupa essas consultas em um cluster de intenção de seleção de ferramentas.
Isso significa que os usuários não estão apenas tentando entender um conceito. Eles estão procurando uma categoria de ferramentas, comparando capacidades e podem estar até prontos para iniciar um teste ou processo de compra.
Etapa 3: A análise de DOM encontra correspondência de intenção fraca
O sistema analisa o DOM da página e descobre que a seção de abertura e a estrutura de H2 ainda explicam principalmente o conceito.
A página não fornece critérios claros de seleção de ferramentas, dimensões de comparação ou casos de uso.
Em outras palavras, a intenção do lado da busca mudou para a seleção de ferramentas, mas a página ainda se comporta como um artigo de explicação de conceito.
Passo 4: O GA4 adiciona evidências comportamentais
O GA4 mostra que a página possui um engajamento relativamente alto, mas com poucos cliques no CTA.
Isso significa que os usuários estão dispostos a ler, mas a página não os direciona de forma fluida para uma ação voltada ao produto.
Passo 5: A base de conhecimento da marca verifica fatos sobre o produto
A base de conhecimento da marca identifica que as capturas de tela (screenshots) do produto na página estão desatualizadas e que algumas descrições de recursos não foram atualizadas para a versão mais recente.
Se isso não for corrigido, o LLM poderá continuar utilizando informações obsoletas do produto ao gerar recomendações de otimização.
Passo 6: Os logs do crawler de IA verificam a acessibilidade técnica
Os logs do crawler de IA mostram que o GPTBot consegue rastrear a página normalmente.
Isso significa que o problema prioritário não é o rastreamento técnico. Os problemas mais urgentes são: se o conteúdo é citável o suficiente, se as informações do produto estão precisas e se o CTA está alinhado com usuários que buscam ferramentas.
Rascunho da Tarefa Final
O sistema gera um rascunho de tarefa como este:
markdown
Página: /blog/top-tools-to-track-ai-mentions-in-llms
Tipo de Problema:
- Baixa correspondência com a intenção de busca (search intent)
- Baixa conversão
- Conteúdo desatualizado
Evidências de Gatilho:
- Consultas de seleção de ferramentas possuem impressões de busca
- A seção de abertura e a estrutura de H2 ainda focam em explicações conceituais
- Engajamento alto, mas cliques no CTA baixos
- A base de conhecimento da marca identificou screenshots desatualizadas
- Rastreamento do GPTBot está normal
Ações Recomendadas:
- Adicionar um módulo de critérios de seleção de ferramentas
- Adicionar uma tabela comparativa de ferramentas
- Atualizar screenshots do produto
- Alterar o CTA genérico de inscrição para "Ver Solução de Monitoramento de Menções em IA"
- Adicionar conteúdo de FAQ
- Adicionar conteúdo passo a passo que seja mais fácil de ser citado por LLMs
Métricas a Monitorar Após a Atualização:
- CTR
- Sessões de busca orgânica
- Cliques no CTA
- Cliques em Demo
- Eventos-chave
- Referências de IA
- Status de rastreamento (crawler)Dessa forma, um artigo passa de um "desempenho de dados pouco claro" para uma tarefa concreta.
A equipe sabe:
- Por que o artigo precisa ser alterado
- Onde está o problema
- O que precisa ser atualizado
- Quem deve ser responsável
- Quais métricas devem ser revisadas posteriormente
7. Monitoramento e Revisão de Desempenho
Um verdadeiro ciclo de crescimento de conteúdo também precisa retroalimentar o sistema com dados de desempenho após a atualização de um artigo.
A versão atual já consegue executar o fluxo de trabalho principal, desde a ingestão de dados até o diagnóstico da página e a geração do rascunho da tarefa.
A próxima etapa é adicionar o rastreamento de desempenho pós-execução, conectando cada atualização de conteúdo às mudanças subsequentes nas métricas.
O sistema registrará:
- Data de geração da tarefa
- Módulos atualizados
- Data de lançamento
- Responsável
- Status da tarefa
- Dados de desempenho de acompanhamento
Isso permite que as equipes avaliem se cada ação de otimização realmente gera resultados.
8. O que ainda precisa ser construído
Neste ponto, o sistema já consegue executar a cadeia de diagnóstico principal. No entanto, várias capacidades ainda precisam ser aprimoradas.
8.1 Agrupamento de Intenção de Consulta (Query Intent Clustering)
A versão atual depende principalmente de similaridade de texto e julgamento baseado em regras. Em indústrias verticais, isso já cobre a maioria das consultas comuns.
Contudo, consultas de cauda longa (long-tail), termos emergentes e consultas semanticamente semelhantes, mas com intenções diferentes, ainda podem ser agrupadas incorretamente.
No futuro, o sistema combinará correspondência de palavras-chave e julgamento baseado em LLM para classificar os clusters de consulta com mais precisão.
Para clusters de intenção com baixa confiança, o sistema os marcará automaticamente como "confirmação manual necessária", evitando que tarefas incorretas sejam geradas quando as evidências forem insuficientes.
8.2 Atualizações Automáticas da Base de Conhecimento da Marca
A base de conhecimento atual da marca ainda é mantida principalmente por importação manual. Isso funciona bem para centralizar informações principais, como funcionalidades do produto, preços, capturas de tela, respostas de FAQ e padrões de mensagens para concorrentes.
Mas, a longo prazo, a base de conhecimento não pode depender apenas de manutenção manual.
O próximo passo é conectar logs de mudanças (changelogs) do produto, dados de CMS ou fontes de documentação interna, para que a versão da base de conhecimento atualize automaticamente conforme o produto evolui.
Isso tornará a verificação de conteúdo desatualizado menos dependente de revisão manual. O sistema também será capaz de identificar mais rapidamente recursos obsoletos, screenshots antigos, preços incorretos e descrições de produtos que não correspondem mais às mensagens atuais.
8.3 Rastreamento de Desempenho
O sistema já consegue determinar qual artigo deve ser atualizado, por que deve ser atualizado, onde deve ser alterado e como gerar uma tarefa de otimização baseada em evidências.
O próximo passo é adicionar o rastreamento de desempenho após a execução da tarefa e conectar cada atualização de conteúdo às mudanças futuras nas métricas.
Uma vez concluído, as equipes de conteúdo poderão entender:
- Se uma otimização realmente criou crescimento
- Quais tipos de atualização são mais eficazes
- Quais páginas ainda precisam de iteração adicional
Conclusão
O objetivo deste sistema de diagnóstico de crescimento de conteúdo não é fornecer mais um relatório de SEO.
O seu objetivo é transformar a otimização de tráfego orgânico num processo que seja:
- Executável
- Rastreável
- Revisável
- Conectado aos resultados de negócio
Esta abordagem conecta dados de pesquisa, conteúdo de páginas, comportamento do utilizador, factos da marca, visibilidade em AI/GEO, tarefas de otimização e feedback de desempenho num ciclo fechado.
Como resultado, a equipa de conteúdo deixa de receber instruções vagas como "otimizar o artigo".
Em vez disso, passam a compreender claramente:
- Por que a página precisa de ser alterada
- Onde está o problema
- O que deve ser atualizado
- Quem deve executar a tarefa
- Quais métricas devem ser verificadas após a atualização
GitHub: github.com/dageno-ai/organic-content-intelligence
Se também está a construir um website independente para mercados internacionais, com foco no crescimento de conteúdo ou pesquisa por IA, e gostaria de discutir esta solução ou saber mais sobre os detalhes de implementação do sistema, pode adicionar o WeChat: dudulhc.
About the Author

Atualizado por
Dageno
Related Articles
2026 Relatório de Pesquisa sobre Status e Tendências GEO para a Indústria de Guindastes

Tim • May 22, 2026
Introdução ao Centro de Diagnóstico Dageno AI (1) - Traduzindo sinais complexos de IA em crescimento
Tim • May 22, 2026
Dageno AI lança quadros de tarefas multiagentes, atualizações de MCP e agentes de prompt mais inteligentes

Ye Faye • May 25, 2026
Dageno Agência Parceira Manual: Escale Sua Agência com Crescimento Potencializado por IA
Tim • May 22, 2026